
RooKie_Z P7 基于Verilog CPU的MIPS微体系设计文档
写在前面
这是RooKie_Z的P7基于Verilog CPU的MIPS微体系设计文档,在课上测试中本CPU取得了 满分💯的成绩。
总体设计概述
本次要求实现的指令集为add, sub, and, or, slt, sltu, lui,addi, andi, ori,lb, lh, lw, sb, sh, sw,mult, multu, div, divu, mfhi, mflo, mthi, mtlo,beq, bne, jal, jr,mfc0, mtc0, eret, syscall ,在P6的基础上新增加了mfc0, mtc0, eret, syscall。
CPU部分与P6相比添加了重要模块CP0协处理器,其余的端口定义和转发、阻塞规则与P6相同,详见附带的P6设计文档,在此处不再赘述
考虑到宏观PC的处理,我把CP0协处理器放置在了M级
数据通路

添加转发后的数据通路

CP0插入流水线与异常码流水

做这样设计的原因如下:
我们称M级为宏观级. F, D, E级的指令”未曾执行”, M级指令“正在执行”, W级指令“执行完毕”. 相当于把流水线CPU封装为一个单周期 CPU.
MIPS微系统整体设计

关键模块介绍
CPU部分与P6相比添加了重要模块CP0协处理器,其余的端口定义和转发、阻塞规则与P6相同,详见附带的P6设计文档,在此处不再赘述。
CP0协处理器
简单介绍
协处理器 CP0,包含 3个 32 位寄存器,用于支持中断和异常。
端口定义
| 端口 | 输入/输出 | 位宽 | 描述 |
|---|---|---|---|
| A1 | I | 5 | 指定 4 个寄存器中的一个,将其存储的数据读出到 RD |
| A2 | I | 5 | 指定 4 个寄存器中的一个,作为写入的目标寄存器 |
| CP0in | I | 32 | 写入寄存器的数据信号 |
| PC | I | 32 | 目前传入的下一个 EPC 值 |
| ExcCodeIn | I | 5 | 目前传入的下一个 ExcCode 值 |
| isInDelaySlot | I | 32 | 目前传入的下一个 BD 值 |
| HWInt | I | 6 | 外部硬件中断信号 |
| WE | I | 1 | 写使能信号,高电平有效 |
| EXLClr | I | 1 | 传入 eret 指令时将 SR 的 EXL 位置 0 ,高电平有效 |
| clk | I | 1 | 时钟信号 |
| reset | I | 1 | 同步复位信号 |
| Req | O | 1 | 输出当前的中断请求 |
| EPCOut | O | 32 | 输出当前 EPC 寄存器中的值 |
| CP0out | O | 32 | 输出 A 指定的寄存器中的数据 |
功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 同步复位 | 当时钟上升沿到来且同步复位信号有效时,将所有寄存器的值设置为 0x00000000。 |
| 2 | 读数据 | 读出 A1 地址对应寄存器中存储的数据到 RD;当 WE 有效时会将 WD 的值会实时反馈到对应的 RD,当 ERET 有效时会将 EXL 置 0,即内部转发。 |
| 3 | 写数据 | 当 WE 有效且时钟上升沿到来时,将 WD 的数据写入 A2 对应的寄存器中。 |
| 4 | 中断处理 | 根据各种传入信号和寄存器的值判断当前是否要进行中断,将结果输出到 IntReq。 |
异常处理流程:
将异常码ExcCode、是否处于延迟槽中的判断信号isInDelaySlot和当前PC(如果时取指地址异常则传递错误的PC值)一直跟着流水线到达M级直至提交至CP0,由CP0综合判断分析是否响应该异常
如果需要响应该异常,则CP0输出Req信号置为1,此时FD、DE、DM、MW寄存器响应Req信号,清空Instr,将PC值设为0x4180,然后输入F级的NPC也被置为0x4180,下一条指令从0x4180开始执行
当外设和系统外部输入中断信号时,CP0同样也会确认是否响应该中断,然后把Req置为1,执行相同的操作。
至于如何处理这个异常信号呢?Well,只需要跳到0x4180,接下来就是课程组的异常处理程序的工作了。
下面是P6的实验报告的部分内容:
所有的流水线寄存器均需要添加isInDelaySlot, Eret, Syscall, ExcCode的传递。
命名规则
- 对于各模块文件,均采用对于元件的文件命名,均为
流水线层级_元件英文简称,例如D_GRF.v,E_ALU.v等,实例化时命名为大写首字母小写英文名,例如Alu,Grf等 - 对于流水线寄存器文件命名为
两边的流水线层级_REG,例如FD_REG.v,DE_REG.v,实例化时命名为大写英文层级,例如FD - 每一级的控制信号和临时的
wire均以本级的名称开头,如E_ALUOp,M_DMOp等 - 在流水线中参与流水的信息遵从以下约定(以D级为例)
PC和Instr命名以流水线层级开头,如D_PC,D_Instr- 寄存器地址分别为
D_rs_addr,D_rt_addr,读出数据为D_rs,D_rt - 转发得到的寄存器数据(直接读取也视为一种转发)记作
D_FWD_rs_data,D_FWD_rt_data - 即将写入的寄存器地址为
E_A3,即将写入的数据记作E_WD,选择信号为E_WDSel
F级(取指)
PC(程序计数器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| NPC[31:0] | I | 待写入PC的指令地址 |
| clk | I | 时钟信号 |
| reset | I | 同步复位信号 |
| PC_WE | I | PC的写使能 |
| PC | O | 当前指令地址 |
然后与mips_txt.v交互获得当前指令
1 | F_PC _pc( |
FD_REG(F/D级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | I | 时钟信号 |
| reset | I | 同步复位信号 |
| flush | I | 寄存器刷新信号(阻塞时使用) |
| F_PC | I | F级PC的指令地址 |
| F_Instr[31:0] | I | 时钟信号 |
| D_PC | O | D级PC的指令地址 |
| D_Instr[31:0] | O | 32位的指令值 |
D级(译码)
- 本级需要处理来自E, M, W级的转发,其中W级为寄存器内部转发,另外两个分别是
D_FWD_rs,D_FWD_rt,在CMP和NPC中需要用 - 本级的输入是来自F级的
PC和Instr,输出是D_rs,D_rt,D_Ext_Out,D_PC和D_Instr,这些参与流水,还有输出到F级的NPC - 本级元件较多,是最复杂的一级
D_GRF
端口说明
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| A1[4:0] | I | 5位地址输入信号,将其储存的数据读出到RD1 |
| A2[4:0] | I | 5位地址输入信号,将其储存的数据读出到RD2 |
| A3[4:0] | I | 5位地址输入信号,将其作为写入数据的目标寄存器 |
| RD1[31:0] | O | 输出A1指定的寄存器中的32位数据 |
| RD2[31:0] | O | 输出A2指定的寄存器中的32位数据 |
| WD[31:0] | I | 32位数据输入信号 |
| clk | I | 时钟信号 |
| reset | I | 同步复位信号,将32个寄存器中的数据清零;1:复位;0:无效 |
- 这次删去了
WE写使能信号,因为如果我们不写寄存器,可以把A3设为0,就相当于不写寄存器了
Ps :这是我灵光一现想到的办法,受了P4课上访存指令的启发,如果有指令要在读出之后针对数据判断是否写入GRF,那么WE信号不仅要一直参与流水,还要用于控制每级的转发与阻塞,利用0寄存器的特点就可以规避这一切的麻烦!!!
控制信号说明
1. D_A3
直接给出待写入寄存器的地址,弃用了在P4中利用A3Sel进行选择的设计,这是因为P5采用分布式译码,每一级都需要A3的信息,因此在CTRL里面直接集成了
2. D_WDSel
| 控制信号值 | 功能 |
|---|---|
WDSel_DMout |
选择写入寄存器的数据来自DM |
WDSel_ALUout |
选择写入寄存器的数据来自ALU运算结果 |
WDSel_PC8 |
选择写入寄存器的数据为当前流水线层级中的PC+8 |
D_EXT
将16位二进制数进行零扩展或符号扩展到32位
控制信号说明
| 控制信号值 | 功能 |
|---|---|
EXT_unsigned |
零扩展 |
EXT_signed |
符号扩展 |
D_CMP(分支比较)
参考P3中CPU内BranchDefine子电路生成的CMP模块,来生成jump信号,判断分支是否跳转,link是否写入
目前实现了beq, bne, bgtz, bltz等指令
代码实现:
1 |
|
端口说明
| 端口名称 | 方向 | 功能描述 |
|---|---|---|
| rs[31:0] | I | 转发后$rs寄存器的值 |
| rt[31:0] | I | 转发后$rt寄存器的值 |
| CMPOp[2:0] | I | 控制信号 |
| jump | O | 指示分支是否跳转 |
D_NPC(次地址计算)
有了CMP之后,NPC的功能也更加简洁,只需根据NPCOp和jump信号输出NPC信号的值就行
实际上NPC横跨了F级和D级两级,因为同时会输入F_PC和D_PC,前者正常跳转F_PC+4用,后者则用于流水PC值,后面转发PC+8的时候用
这次我们弃用了P4中直接输出PC+4的设计,转而让PC信号参与流水,在需要转发时计算PC+8
端口说明
| 端口名称 | 方向 | 功能描述 |
|---|---|---|
| F_PC[31:0] | I | 32位输入当前F级地址 |
| D_PC[31:0] | I | 32位输入当前D级地址 |
| imm[31:0] | I | 32位立即数 |
| jump | I | 指示b类型指令是否跳转 |
| NPCOp[2:0] | I | 控制信号 |
| RD1_rs[31:0] | I | $ra寄存器保存的32位地址 |
| NPC[31:0] | O | 32位输出次地址 |
控制信号说明
| 控制信号值 | 功能 |
|---|---|
NPC_pc4 |
NPC = F_PC+4 |
NPC_b |
执行beq等b类指令 |
NPC_jal |
执行j,jal指令 |
NPC_jalr |
执行jalr,jr指令 |
DE_REG(D/E级流水线寄存器)
输入
D_PC,D_Instr,D_Ext_Out,此外上一级的$rs和$rt的值也要参与流水,即D_FWD_rs,D_FWD_rt需要参与流水,这是由于指令序列sw, nop, add的存在,sw在M级需要使用$rt的数据,但是在E级不会再进行转发(因为在D级已经转发过了),因此需要让正确的$rt值参与流水输出
E_PC,E_Instr,E_Ext_Out,E_rs,E_rt,ALU需要这些信息
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | I | 时钟信号 |
| reset | I | 同步复位信号 |
| flush | I | 寄存器刷新信号(阻塞时使用) |
| D_PC[31:0] | I | D级PC的指令地址 |
| D_Instr[31:0] | I | 32位的指令值 |
| D_Ext_Out[31:0] | I | 16位立即数经EXT扩展的结果 |
| D_rs[31:0] | I | 32位的寄存器数据 |
| D_rt[31:0] | I | 32位的寄存器数据 |
| E_PC[31:0] | O | E级PC的指令地址 |
| E_Instr[31:0] | O | 32位的指令值 |
| E_Ext_Out[31:0] | O | 16位立即数经EXT扩展的结果 |
| E_rs[31:0] | O | 32位的寄存器数据 |
| E_rt[31:0] | O | 32位的寄存器数据 |
E_ALU
- 相比于P4,ALU做了很大的变动,添加了
ALUSrcA信号选择A运算数的来源,这是为了便于扩展sll和sllv类指令的原因取消了shamt信号,shamt信号从ALUSrcB中选择进入ALU中
端口说明
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| A[31:0] | I | 32位输入运算数A |
| B[31:0] | I | 32位输入运算数B |
| ALUOp[4:0] | I | 控制信号 |
| ALUOut[31:0] | O | 32位输出运算结果 |
控制信号说明
1. ALUOp
具体见代码,已实现绝大多数计算功能。
| 控制信号值 | 功能 |
|---|---|
ALU_add |
执行加法运算 |
ALU_sub |
执行减法运算 |
ALU_or |
执行逻辑或运算 |
ALU_lui |
执行lui指令 |
2. ALUSrcA
| 控制信号值 | 功能 |
|---|---|
SrcA_rt |
对于sll和sllv等移位指令,选择$rt的值 |
SrcA_rs |
对于其他大部分运算指令,采用 $rs的值 |
3. ALUSrcB
| 控制信号值 | 功能 |
|---|---|
SrcB_rt |
选择处理完转发后$rt寄存器中的值进行运算 |
SrcB_imm |
选择立即数进行运算 |
SrcB_shamt |
使用{27'b0, E_ALUshamt}得到32为扩展移位数 |
SrcB_rs |
考虑到sllv指令要求可变的位移数,这里可以选择{27'b0, E_FWD_rs_data[4:0]},即$rs寄存器中的数据作为移位数 |
E_MDU(乘除单元)
端口说明
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | I | 时钟信号 |
| reset | I | 复位信号 |
| MDUOp[2:0] | I | 控制信号 |
| D1[31:0] | I | 32位输入运算数A |
| D1[31:0] | I | 32位输入运算数B |
| Start | I | 开始运算的指示信号 |
| Busy | O | 是否处于运算过程中 |
| HI[31:0] | O | 32位HI寄存器值结果 |
| LO[31:0] | O | 32位LO寄存器值结果 |
控制信号说明
1. MDUOp
| 控制信号值 | 功能 |
|---|---|
MDU_mult |
乘法运算 |
MDU_div |
除法运算 |
MDU_multu |
无符号乘法运算 |
MDU_divu |
无符号除法运算 |
MDU_mfhi |
mfhi指令 |
MDU_mflo |
mflo指令 |
MDU_mthi |
mthi指令,把D1的值赋给HI寄存器中 |
MDU_mtlo |
mtlo指令,把D1的值赋给LO寄存器中 |
注意:
当已经发生中断或异常时,Req信号置高,乘除槽停止工作,mult, multu, div, divu不再进行。
EM_REG(E/M级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | I | 时钟信号 |
| reset | I | 同步复位信号 |
| flush | I | 寄存器刷新信号(阻塞时使用) |
| E_PC[31:0] | I | E级PC的指令地址 |
| E_Instr[31:0] | I | 32位的指令值 |
| E_Ext_Out[31:0] | I | 16位立即数经EXT扩展的结果 |
| E_rt[31:0] | I | 32位的寄存器数据 |
| E_ALU_Out[31:0] | I | 32位的ALU运算结果 |
| E_MDU_Out[31:0] | I | 32位的MDU运算结果 |
| M_PC[31:0] | O | M级PC的指令地址 |
| M_Instr[31:0] | O | 32位的指令值 |
| M_Ext_Out[31:0] | O | 16位立即数经EXT扩展的结果 |
| M_ALU_Out[31:0] | O | 32位的ALU运算结果 |
| M_MDU_Out[31:0] | O | 32位的MDU运算结果 |
| M_rt[31:0] | O | 32位的寄存器数据 |
M级(储存)
- 输入
E_PC,E_Instr,此外上一级的ALUOut参与流水,即E_ALU_Out,E_Ext_Out需要参与流水,这是因为ALUOut可能是待写入或读取的内存地址,另外,上一级的rt值需要参与流水,因此还需要输入E_FWD_rt,这是因为sw指令会向内存中写入$rt的数据 - 输出
M_PC,M_Instr,M_ALU_Out,M_DM_Out,M_MDU_Out
M_DM(数据储存器)
DM已经不需要自行实现,调用mips_txt.v中的接口即可利用BE模块处理待写入数据,使其支持按半字、字节、字储存
利用DE模块处理DM返回的数据,使其可以按照不同要求存入寄存器
M_BE
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| BEOp[1:0] | I | 控制信号 |
| Addr[31:0] | I | 地址信息,用于处理半字、字节 |
| rt_data[31:0] | I | 读取的寄存器数据,待处理 |
| DMWr | I | 写使能 |
| m_data_byteen[3:0] | O | 控制写入半字、字节的位置位置 |
| m_data_wdata[31:0] | O | 待写入数据 |
M_DE
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| DEOp[1:0] | I | 控制信号 |
| Addr[31:0] | I | 地址信息,用于处理半字、字节 |
| m_data_rdata[31:0] | I | mips_txt.v返回的DM中的数据 |
| DMout[31:0] | O | 处理之后的正确的读取数据 |
与接口进行交互
1 | // 与DM交互 |
W级(回写)
MW_REG(M/W级流水线寄存器)
| 信号名称 | 方向 | 功能描述 |
|---|---|---|
| clk | I | 时钟信号 |
| reset | I | 同步复位信号 |
| flush | I | 寄存器刷新信号(阻塞时使用) |
| M_PC[31:0] | I | M级PC的指令地址 |
| M_Instr[31:0] | I | 32位的指令值 |
| M_DM_Out[31:0] | I | 从内存中读取的值 |
| M_ALU_Out[31:0] | I | 32位的ALU运算结果 |
| W_PC[31:0] | O | W级PC的指令地址 |
| W_Instr[31:0] | O | 32位的指令值 |
| W_DM_Out[31:0] | O | 从内存中读取的值 |
| W_ALU_Out[31:0] | O | 32位的ALU运算结果 |
数据通路分析
| 指令 | opcode | funct | NPCOp | A3Sel | WDSel | EXTOp | GRFWE | ALUSRCB | ALUOp | DMWr | DMOp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| add | 000000 | 100000 | NPC_PC4 |
A3Sel_rd |
WDSel_ALUout |
X | 1 | SrcB_rt |
ALU_add |
0 | X |
| sub | 000000 | 100010 | NPC_PC4 |
A3Sel_rd |
WDSel_ALUout |
X | 1 | SrcB_rt |
ALU_sub |
0 | X |
| ori | 001101 | X | NPC_PC4 |
A3Sel_rt |
WDSel_ALUout |
EXT_unsigned |
1 | SrcB_imm |
ALU_or |
0 | X |
| lw | 100011 | X | NPC_PC4 |
A3Sel_rt |
WDSel_DMout |
EXT_signed |
1 | SrcB_imm |
ALU_add |
0 | DM_w |
| sw | 101011 | X | NPC_PC4 |
X | WDSel_DMout |
EXT_signed |
0 | SrcB_imm |
ALU_add |
1 | DM_w |
| beq | 000100 | X | NPC_branch |
X | X | X | 0 | X | X | 0 | X |
| lui | 001111 | X | NPC_PC4 |
A3Sel_rt |
WDSel_ALUout |
X | 1 | SrcB_imm |
ALU_lui |
0 | X |
| jal | 000011 | X | NPC_jal |
A3Sel_ra |
WDSel_PC8 |
X | 1 | X | X | 0 | X |
| jr | 000000 | 001000 | NPC_jalr |
X | X | X | 0 | X | X | X | X |
本CPU采用分布式译码,在每一级均设有译码器,解码出各级所需信息
顶层模块设计
Bridge
系统桥是处理CPU与外设(两个计时器)之间信息交互的通道
CPU中store类指令需要储存的数据经过BE处理后会通过m_data_addr, m_data_byteen, m_data_wdata三个信号输出到桥中,桥会根据写使能m_data_byteen和地址m_data_addr来判断到底写的是内存还是外设,然后给出正确的写使能
load类指令则是全部把地址传递给每个外设和DE中,然后桥根据地址选择从应该反馈给CPU从哪里读出来的数据,然后DE再处理读出的数据,反馈正确的结果。
具体端口:
1 | module Bridge( |
代码实现:
1 |
|
Mips模块
其实就是在mips.v中实例化CPU,Bridge,TC0和TC1四个模块相互交互。
冲突处理方法
转发(Forwarding)
对于转发,我们直接采用 AT 法 + 暴力转发,首先要搞明白转发到哪,转发什么。 对于每一个流水线层级,我们要能够确定当前这一级正在执行的指令要写什么数据,向哪里写,因此就要维护 GRFWD (解决转发啥)和 GRFA3 (解决转发到哪)这两个值,我们转发需要去关注的也就是这两个数据,这些信号都可以从 Control 里面译码读出来 简单来说就是,我们需要在每一级都知道本级需要从哪读数据,要写到哪,要写啥,现在不知道没事,总之在这条指令从流水线消失之前,我们肯定知道,并且可以根据这些再经过判断做转发。
在每一个需要用转发数据的地方,我们去比较要用的数据的 GPR 地址和前面正在维护的要写的 GRFA3 的地址,如果相同,那就意味着我们要写的寄存器已经被用了,但是这时前面获得的值显然是错误的,这时候直接转发过去就好了
这里还要考虑优先级的问题,流水线寄存器生成的WD越靠近这条指令,得到的数据就越新,我们就越倾向于优先使用这些数据
利用 AT 法,如果不阻塞就意味着一定能够在使用该寄存器的值之前获得正确的值,如果我们要用的时候,这个正确的值还没有算出来,那肯定不行,这时候我们就阻塞,如果能算出来,那么之前转发的错误的值不用去管它,最后总能得到一个正确的值去覆盖原先错误的值
如果我们还不知道要写的值是啥,那这个时候 GRFA3 就给正确的地址, GRFWD 就给 32'bz ,这时还不能做转发,但是如果写的阻塞模块正确,这个值就不可能被转发,因为这种情况如果出现就已经被阻塞在 D 级了
综合考量各种指令序列,我们得到了转发的旁路:
- D级需求: E->D(如序列
jal-add), M->D(如序列jal-nop-add)(W->D隐藏于GRF的内部转发中); - E级需求: M->E(如序列
add-add), W->E(如序列add-nop-add) - M级需求: W->M(如序列
add-sw)
具体设计见前文图片
代码实现
W to D:
1 | // 寄存器内部转发 |
D级转发处理:
1 | //D级写回数据 |
E级转发处理:
1 | //转发 |
M级转发处理:
1 | //转发 |
阻塞(Stall)
阻塞需要添加一行,关于eret的阻塞
1 | wire M_stall_eret = (D_eret) && ((E_mtc0 && E_rd_ad == 5'd14) || (M_mtc0 && M_rd_ad == 5'd14)); |
对于阻塞的处理,直接采用教程中的AT方法,设计一个 Stall 模块,专门负责处理阻塞时流水线寄存器的 flush 和 WE 信号就行
只在 D 级进行阻塞,阻塞控制器接受当前 D,E,M 级的指令输入,处理分析指令类别,算出当前D的Tuse,和E、M的Tnew,再进行相应的计算
代码实现:
1 | //阻塞逻辑 |
中断异常处理方法
异常码
| 异常与中断码 | 助记符与名称 | 指令与指令类型 | 描述 |
|---|---|---|---|
| 0 | Int (外部中断) |
所有指令 | 中断请求,来源于计时器与外部中断。 |
| 4 | AdEL (取指异常) |
所有指令 | PC 地址未字对齐。 |
PC 地址超过 0x3000 ~ 0x6ffc。 |
|||
AdEL (取数异常) |
lw |
取数地址未与 4 字节对齐。 | |
lh |
取数地址未与 2 字节对齐。 | ||
lh, lb |
取 Timer 寄存器的值。 | ||
| load 型指令 | 计算地址时加法溢出。 | ||
| load 型指令 | 取数地址超出 DM、Timer0、Timer1、中断发生器的范围。 | ||
| 5 | AdES (存数异常) |
sw |
存数地址未 4 字节对齐。 |
sh |
存数地址未 2 字节对齐。 | ||
sh, sb |
存 Timer 寄存器的值。 | ||
| store 型指令 | 计算地址加法溢出。 | ||
| store 型指令 | 向计时器的 Count 寄存器存值。 | ||
| store 型指令 | 存数地址超出 DM、Timer0、Timer1、中断发生器的范围。 | ||
| 8 | Syscall (系统调用) |
syscall |
系统调用。 |
| 10 | RI(未知指令) |
- | 未知的指令码。 |
| 12 | Ov(溢出异常) |
add, addi, sub |
算术溢出。 |
地址范围
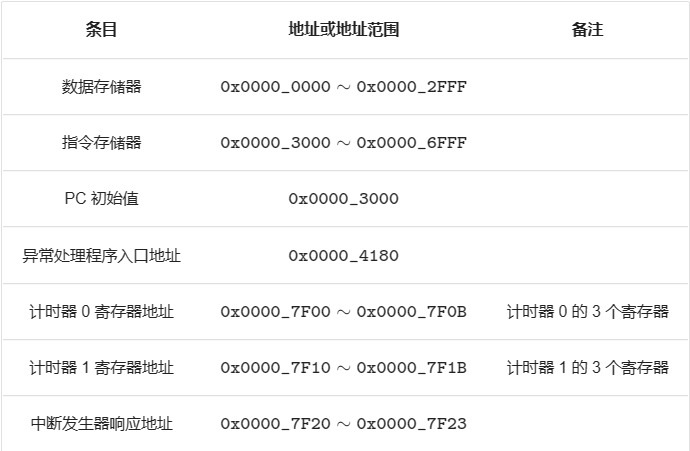
异常处理流程:
具体实现:
将异常码ExcCode、是否处于延迟槽中的判断信号isInDelaySlot和当前PC(如果时取指地址异常则传递错误的PC值)一直跟着流水线到达M级直至提交至CP0,由CP0综合判断分析是否响应该异常
如果需要响应该异常,则CP0输出Req信号置为1,此时FD、DE、DM、MW寄存器响应Req信号,清空Instr,将PC值设为0x4180,然后输入F级的NPC也被置为0x4180,下一条指令从0x4180开始执行
当外设和系统外部输入中断信号时,CP0同样也会确认是否响应该中断,然后把Req置为1,执行相同的操作。
至于如何处理这个异常信号呢?Well,只需要跳到0x4180,接下来就是课程组的异常处理程序的工作了。
测试方案
没有自动评测工具,通过对特定的异常和中断编写程序进行测试
异常测试
取指异常
1 |
|
其它异常
1 |
|
计时器功能测试
1 |
|
延迟槽异常测试
1 |
|
一组异常覆盖100%的数据:
1 |
|
中断测试
其实没有什么特殊的测试方案,就是把中断的PC值取在各个地方,取在各种指令之前或之后,进行测试就行,看是否断在相应的地方。
提供一组测试方案
说明
1 | - 0x3010 宏观pc对应写GRF指令时,给予外部中断 |
样例:
1 |
|
相应tb:
1 |
|
思考题
请查阅相关资料,说明鼠标和键盘的输入信号是如何被 CPU 知晓的?
键盘和鼠标本质上都是输入设备,其自身的内部有一些微处理器来控制自己与主机之间的信息交互。而在CPU看来,外部信号会经过很多层级传入到内部,而内部的信息也会经过很多层级传出至外部。这些层级由外至内大致可以分为主存->cache(->bridge)->CPU。
每个设备都需要驱动程序的,只不过驱动程序有的在电脑系统内,有的却需另外按装,比如:无线键鼠套装,驱动程序已经在USB头上,我们叫它免驱设备。如果没有这些指定驱动程序的话,电脑是无法识别内容的。
请思考为什么我们的 CPU 处理中断异常必须是已经指定好的地址?如果你的 CPU 支持用户自定义入口地址,即处理中断异常的程序由用户提供,其还能提供我们所希望的功能吗?如果可以,请说明这样可能会出现什么问题?否则举例说明。(假设用户提供的中断处理程序合法)
因为中断异常处理程序是在程序所有程序运行前就已经写好了,设置固定的地址,就能保证异常或者中断来临的时候呢能够跳转到正确的地址进行处理。
如果由用户提供中断异常处理程序的话,它跳转的地址也是计算出来的,但是如果在算跳转地址的时候出现了错误,那就无法正常进行异常处理行为。
为何与外设通信需要 Bridge?
因为我们的CPU可能会与许多外设相连,如果为每一个外设提供一套数据和地址,就会让CPU变得非常复杂。这里Bridge充当一个交互的角色,将多个外设与CPU连起来,这样我们的CPU只用提供一个接口即可。
添加外设时,外设也只需要体现在入口地址的不同而不需要改变CPU的内部结构,让CPU访问外设只需通过地址,这样也是体现了”高内聚,低耦合”的原则。
请阅读官方提供的定时器源代码,阐述两种中断模式的异同,并针对每一种模式绘制状态移图。
两种中断,模式0为定时中断,模式1为周期性中断。区别在于倒计时达到0之后的状态。
区别: 两种中断,模式0为定时中断,模式1为周期性中断。区别在于倒计时达到0之后的状态。
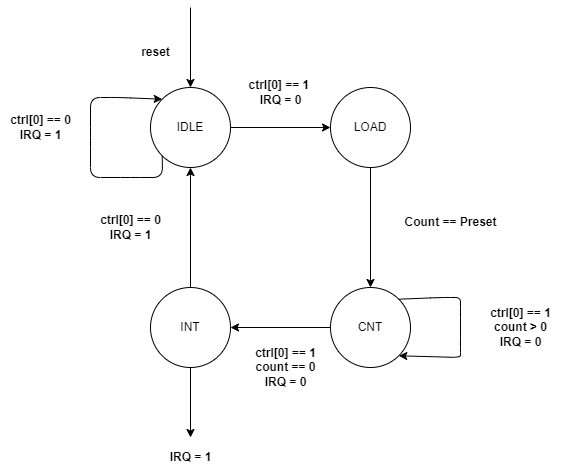
计数器模式 0:
当计数器倒计数为 0 后,计数器停止计数,Ctrl 寄存器的计数使能自动变为 0,并且中断信号始终保持有效,直到屏蔽中断或重新开始计数。该模式通常用于定时中断。
状态转移图如下:
计数器模式 1:
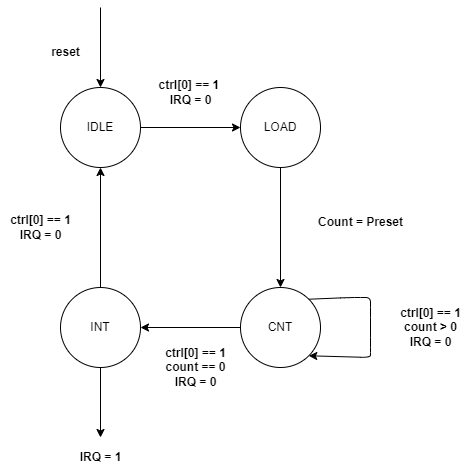
当计数器倒计时为 0 后,会自动的重新读取 preset 寄存器的值,然后重新开始倒计数。在这种模式下,中断信号只会产生一个周期。该模式通常用于产生周期性中断。
状态转移图如下:
倘若中断信号流入的时候,在检测宏观 PC 的一级如果是一条空泡(你的 CPU 该级所有信息均为空)指令,此时会发生什么问题?在此例基础上请思考:在 P7 中,清空流水线产生的空泡指令应该保留原指令的哪些信息?
可能会出现宏观PC和EPC的错误,而且延迟槽标记信号也会出现问题。
如果是中断或者异常指令造成的流水线清空,应该保持原有的PC值,以保证宏观PC的正确。
如果是阻塞造成的DE级流水线清除,应该要保持原有的PC并且保持原有的BD标志信号。
为什么
jalr指令为什么不能写成jalr $31, $31?具体实现上: 因为
jalr $31,$31,是要同时读写$31,而GRF具有内部转发,也就是在其他i1与i2同时读写一个寄存器时,会直接把写的数据加载到读端口,如此jalr就读出的是PC+4,并没有实现原先的跳转功能。规范上:
这种操作具有二义性,不知道先跳转还是先链接
指令集要求。寄存器说明符 rs 和 rd 不得相等,因为此类指令在重新执行时不具有相同的效果。执行此类指令的结果是不可预测的。此限制允许异常处理程序在分支延迟槽中发生异常时通过重新执行分支来恢复执行。
RooKie_Z P7 基于Verilog CPU的MIPS微体系设计文档