写在前面 RooKie_Z Compiler 编译器设计文档,本编译器 在最终的竞速中排名第五
代码见https://github.com/rookie-zgy1513/rookie_z-compiler
Update time: 2024年12月3日 星期二 18时19分15秒 CST
“免责声明”
文档撰写要求中要求按照编码前的设计、编码完成之后的修改 的顺序完成各部分撰写
而事实上,我向来偏好调研先于实践,设计早于编码 的代码撰写理念,而这篇设计文档也完全是本人的有感而发,设计用时相较编码用时极长,故代码重构较少,因此,请允许我不采用推荐的格式,按照我的编译器设计完成的思路完成这篇设计文档,不胜感激!!!
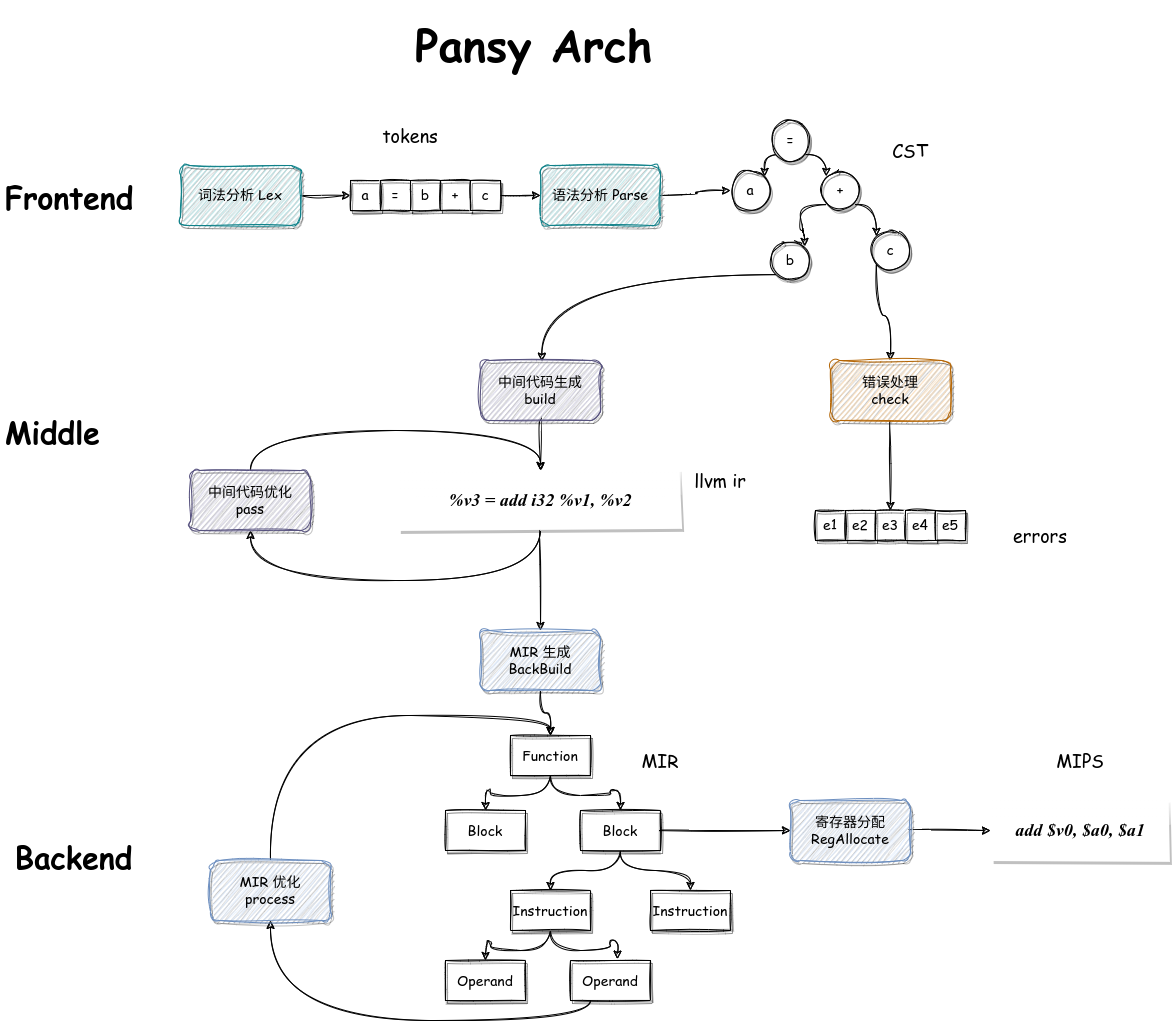
参考编译器介绍 参考了强生学长的 Pansy编译器 ,这是一个简单的编译SysY语言到Mips的编译器。该编译器设计极为精美,架构相当完整,可拓展性强,我的架构主要也模仿了 Pansy编译器
另外,据强生学长介绍,Pansy还有美人之意,这样一看我的代码也属于是东施效颦了😇
总体结构
接口设计 具体的接口层有四层
Tokens -> CST:向前负责,有一个统一的 Parser 用于生成 CST。
CST -> LLVM IR:向后负责,CST 的每个节点实现了相应的 irBuild。
CST -> Errors:向后负责,CST 的每个节点实现了相应的 check。
LLVM IR -> MIR:向前负责,有一个统一的 IrParser 用于生成 MIR。
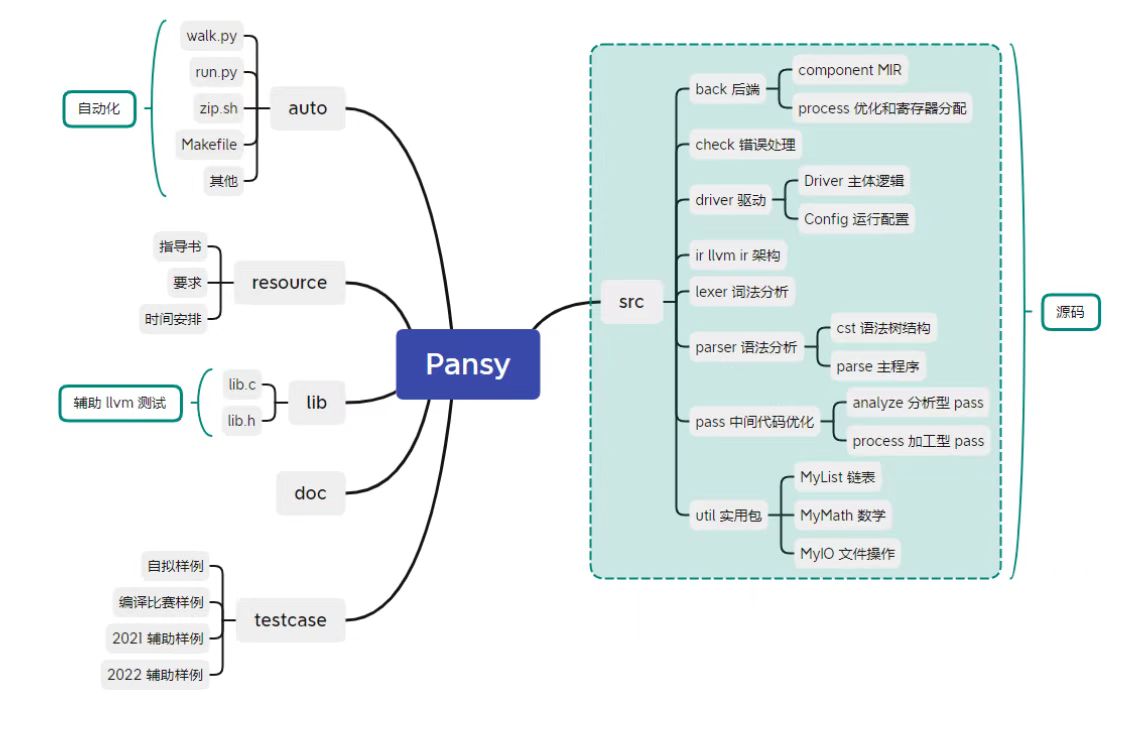
文件组织
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 . ├── Compiler.java ├── back │ ├── Backend.java │ ├── README.md │ ├── component │ │ ├── ObjBlock.java │ │ ├── ObjFunction.java │ │ ├── ObjGlobalVariable.java │ │ └── ObjModule.java │ ├── instruction │ │ ├── ObjBinary.java │ │ ├── ObjBranch.java │ │ ├── ObjCall.java │ │ ├── ObjCoMove.java │ │ ├── ObjComment.java │ │ ├── ObjCompare.java │ │ ├── ObjCondType.java │ │ ├── ObjInstr.java │ │ ├── ObjLoad.java │ │ ├── ObjMove.java │ │ ├── ObjRet.java │ │ ├── ObjShift.java │ │ └── ObjStore.java │ ├── operand │ │ ├── ObjImm.java │ │ ├── ObjLabel.java │ │ ├── ObjOperand.java │ │ ├── ObjPhyReg.java │ │ ├── ObjReg.java │ │ └── ObjVirReg.java │ └── process │ ├── BlockLiveInfo.java │ ├── IrParser.java │ ├── Peephole.java │ └── RegAllocator.java ├── check │ ├── CheckDataType.java │ ├── Checker.java │ ├── ErrorType.java │ ├── FuncInfo.java │ ├── PansyException.java │ ├── README.md │ ├── SymbolInfo.java │ ├── SymbolTable.java │ └── VarInfo.java ├── driver │ ├── Config.java │ └── Driver.java ├── ir │ ├── IrBuilder.java │ ├── IrSymbolTable.java │ ├── README.md │ ├── types │ │ ├── ArrayType.java │ │ ├── DataType.java │ │ ├── FunctionType.java │ │ ├── IntType.java │ │ ├── LabelType.java │ │ ├── PointerType.java │ │ ├── ValueType.java │ │ └── VoidType.java │ └── values │ ├── Argument.java │ ├── BasicBlock.java │ ├── Function.java │ ├── GlobalVariable.java │ ├── Module.java │ ├── User.java │ ├── Value.java │ ├── constants │ │ ├── ConstArray.java │ │ ├── ConstInt.java │ │ ├── ConstStr.java │ │ ├── Constant.java │ │ └── ZeroInitializer.java │ └── instructions │ ├── Add.java │ ├── Alloca.java │ ├── BinInstruction.java │ ├── Br.java │ ├── Call.java │ ├── GetElementPtr.java │ ├── Icmp.java │ ├── Instruction.java │ ├── Load.java │ ├── MemInstruction.java │ ├── Mul.java │ ├── Phi.java │ ├── Ret.java │ ├── Sdiv.java │ ├── Srem.java │ ├── Store.java │ ├── Sub.java │ ├── TerInstruction.java │ └── Zext.java ├── lexer │ ├── Lexer.java │ ├── README.md │ └── token │ ├── Comment.java │ ├── Delimiter.java │ ├── EOFToken.java │ ├── FormString.java │ ├── Identifier.java │ ├── IntConst.java │ ├── Reserved.java │ ├── SyntaxType.java │ └── Token.java ├── parser │ ├── ParseSupporter.java │ ├── Parser.java │ ├── README.md │ ├── SysY.g4 │ └── cst │ ├── AddExpNode.java │ ├── AssignStmtNode.java │ ├── BTypeNode.java │ ├── BlockItemNode.java │ ├── BlockNode.java │ ├── BreakStmtNode.java │ ├── CSTNode.java │ ├── CalleeNode.java │ ├── CondNode.java │ ├── ConditionStmtNode.java │ ├── ConstDeclNode.java │ ├── ConstDefNode.java │ ├── ConstExpNode.java │ ├── ConstInitValNode.java │ ├── ContinueStmtNode.java │ ├── DeclNode.java │ ├── EqExpNode.java │ ├── ExpNode.java │ ├── ExpStmtNode.java │ ├── FuncDefNode.java │ ├── FuncFParamNode.java │ ├── FuncFParamsNode.java │ ├── FuncRParamsNode.java │ ├── FuncTypeNode.java │ ├── InStmtNode.java │ ├── InitValNode.java │ ├── LAndExpNode.java │ ├── LOrExpNode.java │ ├── LValNode.java │ ├── MainFuncDefNode.java │ ├── MulExpNode.java │ ├── NumberNode.java │ ├── OutStmtNode.java │ ├── PrimaryExpNode.java │ ├── RelExpNode.java │ ├── ReturnStmtNode.java │ ├── RootNode.java │ ├── StmtNode.java │ ├── TokenNode.java │ ├── UnaryExpNode.java │ ├── UnaryOpNode.java │ ├── VarDeclNode.java │ ├── VarDefNode.java │ └── WhileStmtNode.java ├── pass │ ├── Pass.java │ ├── PassManager.java │ ├── README.md │ ├── analyze │ │ ├── BuildCFG.java │ │ ├── DomInfo.java │ │ ├── Loop.java │ │ ├── LoopInfo.java │ │ ├── LoopInfoAnalysis.java │ │ └── SideEffectAnalysis.java │ └── refactor │ ├── BranchOpt.java │ ├── DeadCodeEmit.java │ ├── FunctionClone.java │ ├── GCM.java │ ├── GVN.java │ ├── GlobalVariableLocalize.java │ ├── InlineFunction.java │ ├── InstructionSimplify.java │ ├── Mem2reg.java │ └── UselessRetEmit.java └── util ├── MyCompare.java ├── MyIO.java ├── MyList.java ├── MyMath.java ├── MyPair.java └── MyPrintf.java
编译器总体设计 总体结构 通过理论课的学习可以知道,我们通常将编译过程分为如下阶段:
词法分析,语法分析,语义分析,llvm生成,llvm优化,mips生成及优化,其中错误处理贯穿整个前端过程。
接口设计 类似于 Pansy:
具体的接口层有四层
Tokens -> AST:向前负责,有一个统一的 Parser 用于生成 AST。AST -> Symbol:向后负责,AST 的每个节点实现了相应的 visit方法。AST -> Errors:向后负责,AST 的每个节点实现了相应的 visit方法在其中完成错误处理。AST -> LLVM IR:向后负责,AST 的每个节点实现了相应的 BuildIr方法。LLVM IR -> MIPS:向前负责,有一个统一的 MipsBuilder用于生成 MIPS。
文件组织 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 . ├── Compiler.java ├── backend │ ├── MipsBuilder.java │ ├── MipsFactory.java │ ├── components │ │ ├── MipsBlock.java │ │ ├── MipsFunction.java │ │ ├── MipsGlobalVariable.java │ │ └── MipsModule.java │ ├── instructions │ │ ├── MipsBinary.java │ │ ├── MipsBranch.java │ │ ├── MipsCall.java │ │ ├── MipsComment.java │ │ ├── MipsCompare.java │ │ ├── MipsCondType.java │ │ ├── MipsInstruction.java │ │ ├── MipsLoad.java │ │ ├── MipsMacro.java │ │ ├── MipsMove.java │ │ ├── MipsMoveHI.java │ │ ├── MipsRet.java │ │ ├── MipsShift.java │ │ └── MipsStore.java │ ├── operands │ │ ├── MipsImm.java │ │ ├── MipsLabel.java │ │ ├── MipsOperand.java │ │ ├── MipsRealReg.java │ │ ├── MipsVirtualReg.java │ │ └── RegType.java │ ├── reg │ │ ├── BlockLiveVarInfo.java │ │ └── RegAllocator.java │ └── utils │ ├── MipsMathOpt.java │ ├── MipsUtil.java │ ├── Pair.java │ └── Triple.java ├── compiler.zip ├── config.json ├── error │ ├── Error.java │ ├── ErrorHandler.java │ ├── ErrorType.java │ └── ErrorUtil.java ├── exception │ └── LexerException.java ├── frontend │ ├── Lexer.java │ ├── Parser.java │ └── Visitor.java ├── ir │ ├── IrBuilder.java │ ├── IrFactory.java │ ├── IrSymbolTable.java │ ├── IrSymbolTableStack.java │ ├── IrUtil.java │ ├── types │ │ ├── ArrayType.java │ │ ├── CharType.java │ │ ├── FuncType.java │ │ ├── IntType.java │ │ ├── LabelType.java │ │ ├── PointerType.java │ │ ├── ValueType.java │ │ └── VoidType.java │ └── values │ ├── BasicBlock.java │ ├── Function.java │ ├── GlobalVariable.java │ ├── Module.java │ ├── User.java │ ├── Value.java │ ├── constants │ │ ├── ConstArray.java │ │ ├── ConstChar.java │ │ ├── ConstInt.java │ │ ├── ConstString.java │ │ ├── Constant.java │ │ └── ZeroInitializer.java │ ├── instructions │ │ ├── Add.java │ │ ├── Alloca.java │ │ ├── ArithmeticInstruction.java │ │ ├── Br.java │ │ ├── Call.java │ │ ├── GetElementPtr.java │ │ ├── Icmp.java │ │ ├── Instruction.java │ │ ├── Load.java │ │ ├── Mul.java │ │ ├── Phi.java │ │ ├── Ret.java │ │ ├── Sdiv.java │ │ ├── Srem.java │ │ ├── Store.java │ │ ├── Sub.java │ │ ├── Trunc.java │ │ └── Zext.java │ └── pass │ ├── AggressiveDeadCodeEmit.java │ ├── BuildCFG.java │ ├── DeadCodeEmit.java │ ├── DomInfo.java │ ├── GVL.java │ ├── Loop.java │ ├── LoopInfo.java │ ├── Mem2Reg.java │ ├── SideEffectAnalysis.java │ └── UselessRetEmit.java ├── node │ ├── AddExpNode.java │ ├── BTypeNode.java │ ├── BlockItemNode.java │ ├── BlockNode.java │ ├── CharacterNode.java │ ├── CompUnitNode.java │ ├── CondNode.java │ ├── ConstDeclNode.java │ ├── ConstDefNode.java │ ├── ConstExpNode.java │ ├── ConstInitValNode.java │ ├── DeclNode.java │ ├── EqExpNode.java │ ├── ExpNode.java │ ├── ForStmtNode.java │ ├── FuncDefNode.java │ ├── FuncFParamNode.java │ ├── FuncFParamsNode.java │ ├── FuncRParamsNode.java │ ├── FuncTypeNode.java │ ├── InitValNode.java │ ├── LAndExpNode.java │ ├── LOrExpNode.java │ ├── LValNode.java │ ├── MainFuncDefNode.java │ ├── MulExpNode.java │ ├── Node.java │ ├── NodeType.java │ ├── NumberNode.java │ ├── PrimaryExpNode.java │ ├── RelExpNode.java │ ├── StmtNode.java │ ├── StmtType.java │ ├── UnaryExpNode.java │ ├── UnaryOpNode.java │ ├── VarDeclNode.java │ └── VarDefNode.java ├── opt │ └── Peephole.java ├── symbol │ ├── CharSymbol.java │ ├── FuncSymbol.java │ ├── NumSymbol.java │ ├── Symbol.java │ ├── SymbolTable.java │ ├── SymbolTableStack.java │ └── SymbolType.java ├── test │ └── testReg.java ├── token │ ├── Token.java │ └── TokenType.java ├── utils │ ├── Config.java │ ├── IO.java │ └── Phases.java └── 设计文档.md
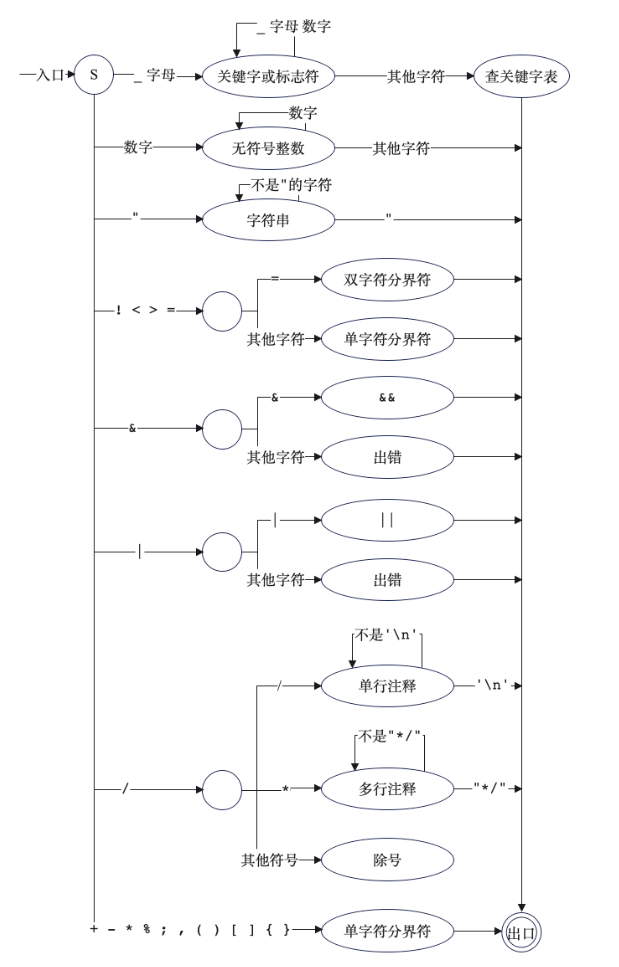
词法分析 大体思路 词法分析部分的主要任务是顺序遍历源程序代码,将其按照文法转化为token序列。
词法分析可以通过正则表达式匹配 或者贪心简化过的DFA 实现,我完成了正则表达式的撰写,但由于我是正则苦手 🫠,最终我选择了后者。
DFA的设计 DFA通过 fronted/Lexer.java实现,我们的单词大致分为四类,分别是保留字、 字符串常量、标识符、分界符。通过贪心匹配不同类别的FIRST集合,即可根据当前字符,确定下面将要处理的单词的大致种类 。
调用 next()方法即可读取下一个token,大致框架如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 public Token next () throws LexerException { currentToken = null ; do { skipWhite(); } while (skipComment()); if (pos > maxLength) { return null ; } char nowChar = inputText.charAt(pos); if (Character.isDigit(nowChar)) { int endPos = pos + 1 ; while (endPos <= maxLength && Character.isDigit(inputText.charAt(endPos))) { endPos++; } String str = inputText.substring(pos, endPos); pos = endPos; currentToken = new Token (str, lineNum, TokenType.INTCON); } else if (isIdentifierNondigit(nowChar)) { int endPos = pos + 1 ; while (endPos <= maxLength && isIdentifierDigit(inputText.charAt(endPos))) { endPos++; } String str = inputText.substring(pos, endPos); pos = endPos; TokenType type = TokenType.isReserved(str); currentToken = new Token (str, lineNum, Objects.requireNonNullElse(type, TokenType.IDENFR)); } else if (nowChar == '\'' ) { int endPos = pos + 1 ; boolean backslashFlag = false ; while (endPos <= maxLength && (inputText.charAt(endPos) != '\'' || (inputText.charAt(endPos) == '\'' && backslashFlag))) { backslashFlag = inputText.charAt(endPos) == '\\' && !backslashFlag; endPos++; } if (endPos > maxLength) { throw new LexerException (lineNum); } endPos++; String str = inputText.substring(pos, endPos); pos = endPos; currentToken = new Token (str, lineNum, TokenType.CHRCON); } else if (nowChar == '\"' ) { int endPos = pos + 1 ; boolean backslashFlag = false ; while (endPos <= maxLength && (inputText.charAt(endPos) != '\"' || inputText.charAt(endPos) == '\"' && backslashFlag)) { backslashFlag = inputText.charAt(endPos) == '\\' && !backslashFlag; endPos++; } if (endPos > maxLength) { throw new LexerException (lineNum); } endPos++; String str = inputText.substring(pos, endPos); pos = endPos; currentToken = new Token (str, lineNum, TokenType.STRCON); } else { TokenType tokenType = null ; int tokenLength = 0 ; String str = "" ; if (TokenType.singleCharList.contains(nowChar)) { tokenType = TokenType.getTokenType((str = inputText.substring(pos, pos + 1 ))); tokenLength = 1 ; } if (pos < maxLength && TokenType.doubleCharList.contains(nowChar)) { TokenType t = TokenType.getTokenType(inputText.substring(pos, pos + 2 )); if (t != null ) { tokenType = t; tokenLength = 2 ; str = inputText.substring(pos, pos + 2 ); } else if (isErrorA(inputText.charAt(pos))) { System.out.println(inputText.charAt(pos) + " " + "我做了错饭" ); ErrorHandler.addError(new Error (ErrorType.a, lineNum)); tokenType = (inputText.charAt(pos) == '&' ) ? TokenType.AND : TokenType.OR; str = (inputText.charAt(pos) == '&' ) ? "&&" : "||" ; tokenLength = 1 ; } } if (tokenType != null ) { currentToken = new Token (str, lineNum, tokenType); pos += tokenLength; } } if (currentToken != null ) { tokenResult.add(currentToken); } return currentToken; }
Token类 为了进行可能的语法拓展,我对于各种 token进行了抽象,建立Token类,该类记录了 Token的原字符串,token的类型,以及其所在行号(供错误处理使用)
1 2 3 4 5 public Token (String content, int lineNum, TokenType type) { this .content = content; this .lineNum = lineNum; this .type = type; }
有关文法设定部分 位于 token/TokenType.java
对于所有 Token标识符,我都加以枚举,定义在枚举类 TokenType里。
此外,为了便于状态机读取当前字符后的进一步状态转移,对于文法中规定的 保留字、以及 单/双分界符$ ==, \ne, \le, \ge, \gt, \lt, !, &, |$,进行建表与划分 。
以上两种信息均为“文法给出的设定”,因此在设计上理应放入一个类中,这使得我们的 Lexer类并不会把文法写死在代码里,便于后续期中期末考试修改文法时,快速完成词法分析部分的修改 。
语法分析 大体思路 语法分析的任务是是读入 token序列,并分析确定其语法结构,最终生成语法树的过程。
[!NOTE]通过理论课我们知道,我们可以使用递归下降分析法来实现语法分析,而由于递归下降子程序本质上是在进行最左推导,因此可能会遇到左递归和回溯的问题。
具体来说: 我为每个非终结符编写一个递归子程序,以完成该非终结符所对应的语法成分的分析与识别任务,若正确识别,则可以退出该非终结符号的子程序,返回到上一级的子程序继续分析;若发生错误,即源程序不符合文法,则要进行相应的错误信息报告以及错误处理。
nextSym()的实现
[!NOTE]
通过理论课的学习我们知道,法分析的推进,本质上是终结符识别进度的推进,因此 nextSym的调用时机应当是成功识别一个终结符后
事实上,在理论课提供的 Pascal语言编译器的语法分析部分,对于 nextSym的设计太过简单,导致示例程序低内聚,高耦合 ,考虑到在语法分析部分就有进行错误处理的需要,我对于 nextSym()程序进行了改写。
具体思路为:将识别终结符,nextSym,以及后续可能的错误处理整合进一个函数当中。
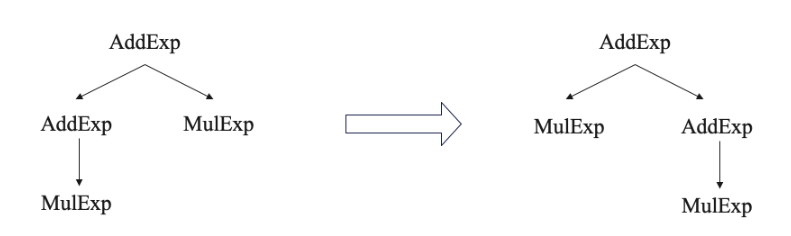
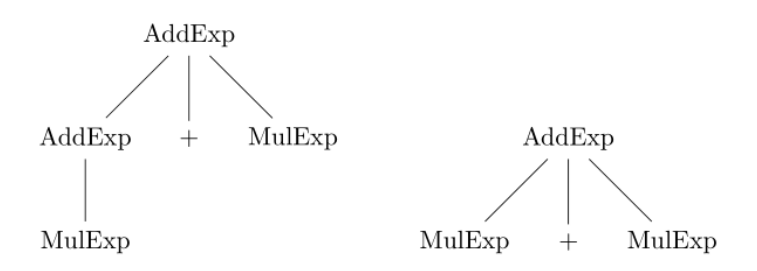
左递归的处理 涉及到左递归的文法主要是关于 Exp系列的非终结符。
1 AddExp -> MulExp | AddExp ('+' | '−' ) MulExp
[!NOTE]
通过理论课的学习我们知道,对于左递归文法,一般有2种处理方式——右递归改写 or 采用扩充的BNF范式
右递归改写 例如:
1 AddExp -> MulExp | MulExp ('+' | '−' ) AddExp
但如此处理是存在潜在风险的,因为修改了文法
扩充的BNF范式 还有一种处理方式是采用BNF范式,修改了文法,直接丢掉 AddExp。
1 AddExp -> MulExp {'+' MulExp}
这种处理方式依然存在风险 ,因为后续的所有编译环节都要相应地使用修改后的文法。
处理方式
[!IMPORTANT]
经过上述分析,考虑到未来 期中期末考试可能涉及的潜在的文法修改与更新,通过参考学长编译器的设计,我决定采用一种更符合实际编译器撰写的方法进行处理,即:
对于上述例子,在扩充的BNF范式的基础上再进一步,把刚刚拆出来的所有 MulExp全部手动组装回左递归的形态。我们利用 java的面向对象特性,将解析出的 MulExp重新组装为 AddExp。
此时左递归对于后续的编译部分不再有影响,因为我们的信息已经全部存储在编译器中,不再受到最左推导的限制。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 public AddExpNode AddExp () { AddExpNode addExpNode = null ; Token opToken = null ; MulExpNode mulExpNode = MulExp(); while (currentToken.type == TokenType.PLUS || currentToken.type == TokenType.MINU) { addExpNode = new AddExpNode (addExpNode, opToken, mulExpNode); opToken = matchToken(currentToken.type); mulExpNode = MulExp(); } return new AddExpNode (addExpNode, opToken, mulExpNode); }
回溯法 对于一般的产生式,我们采用FIRST集来判别即可,但是也有一些不那么友好的产生式,我们难以判别:
选择哪个产生式。
产生式中 {xxx}的重复部分,到底应该何时结束。
重复部分啥时候结束?看看 ),]不就好了?事实上,我们在后续错误处理中采取的,补全的错误局部化策略,迫使我们的程序在 ),]缺失时依然要正常工作。为解决这个问题,我们只得以循环部的FIRST集来判别 。
回到我们的回溯问题来。
回溯,即FIRST也失灵的情况下,我们被迫跳过某个非终结符,对后面的标志性符号进行分析,从而判断选取的产生式分支的手段。
回溯只产生在 Stmt的左值与 Exp判别上:
1 2 3 4 plaintext Stmt -> LVal '=' Exp ';' Stmt -> [Exp] ';' Stmt -> LVal '=' 'getint''('')'';'
在这里,Exp当然可以透过 PrimaryExp推出左值 LVal,FIRST集失灵。
为此,我们要处理掉碍事的 LVal,暴露出后面的 =和 getint。
回溯主要是采用 pinToken()和 reflow()来记录、复原当前游标在token序列的位置。详细代码及注释如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 default -> { if (currentToken.type == TokenType.SEMICN) { tokens.add(matchToken(TokenType.SEMICN)); type = StmtType.EXP; } else { pinToken(); LValNode lValNode = LVal(); if (currentToken.type == TokenType.ASSIGN) { nodes.add(lValNode); tokens.add(matchToken(TokenType.ASSIGN)); if (currentToken.type == TokenType.GETINTTK) { tokens.add(matchToken(TokenType.GETINTTK)); tokens.add(matchToken(TokenType.LPARENT)); tokens.add(matchToken(TokenType.RPARENT)); tokens.add(matchToken(TokenType.SEMICN)); type = StmtType.LVALGETINT; } else if (currentToken.type == TokenType.GETCHARTK) { tokens.add(matchToken(TokenType.GETCHARTK)); tokens.add(matchToken(TokenType.LPARENT)); tokens.add(matchToken(TokenType.RPARENT)); tokens.add(matchToken(TokenType.SEMICN)); type = StmtType.LVALGETCHR; } else { nodes.add(Exp()); tokens.add(matchToken(TokenType.SEMICN)); type = StmtType.LVALASSIGN; } } else { reflow(); ExpNode expNode = Exp(); nodes.add(expNode); tokens.add(matchToken(TokenType.SEMICN)); type = StmtType.EXP; } } }
Node类——前端🔗中端的关键 node类是语法分析中,语法树的结点,记录了语法分析的结果
对于每一个非终结符,都建立一个 node类。所有 node类都继承了抽象父类 Node。
Node规定了所有 node类都要实现的三个方法,用于在遍历语法树时执行相应的动作 (即递归下降时的动作符号):
print()方法,透过遍历语法树,输出语法分析结果至文件。visit()方法,透过遍历语法树,检查错误并记录。buildIr()方法,透过遍历语法树,生成 llvm代码。
语义分析&&错误处理 在当前前端阶段,我们要求生成的符号表还是过于简易,实际上,只对于错误处理有指导意义,可以说,我们的初步语义分析,就是为了错误处理准备的。
错误总论 语法&&词法错误 并不是所有的错误都是语义错误,常见的语义错误有“变量重命名,变量未定义”等,这些错误是可以通过词法分析和语法分析的,不会造成语法分析的错误。但是有些错误,是没有办法通过词法分析和语法分析的,有如下这些类
编号
类型
原因
a
非法符号
无法通过词法分析
i
缺少分号
无法通过语法分析
j
缺少右小括号
无法通过语法分析
k
缺少右中括号
无法通过语法分析
对于 A类错误,此类错误直接处理也不会导致语法,语义分析无法进行,故直接处理:
1 2 3 4 ErrorHandler.addError(new Error (ErrorType.a, lineNum)); tokenType = (inputText.charAt(pos) == '&' ) ? TokenType.AND : TokenType.OR; str = (inputText.charAt(pos) == '&' ) ? "&&" : "||" ; tokenLength = 1 ;
而对于 i,j,k这些导致语法分析进行不下去的错误一定需要被“包容”,否则就坚持不到错误处理流程了。这种包容设置还有一种“补充”的意味在里面。但是最难的其实是缺失符号对于正常语法解析的影响,缺失符号会让原本就很困难的语法分析变得更加困难,这是因为语法分析本就需要依靠符号确定解析的分支,缺少符号会让这个过程变得模糊不清,这也是像 i, j, k 这类错误并不太多的原因,因为一旦多了,就会导致解析困难。
在三种缺失中,以缺少右中括号最为好处理,中括号意味着维度信息,只要有左中括号,那么右中括号一定是可以补上的,基本上无脑就可以了。
但是对于缺失分号和小括号,有可能造成解析分支的判断不当。所以需要进行回退处理(如果不回退的话就要改写文法,而且文法改的毫无语义意义)。
对于缺失分号,有无法区分赋值语句和表达式的问题。
1 2 3 4 5 6 7 i + 1 ; a = b + c; i + 1 a = b + c;
这就意味着没法通过前瞻(即“在分号前有一个等于号“)来确定是否是赋值语句。所以只能通过“尝试解析-判断 LAST”的方法进行。
对于 return 语句,可能也有这种现象,虽然应该被语义约束了
1 2 3 4 5 6 7 return ;a; return a;
对于 Callee 语句,也是这样(应该也被约束了),这里应该是同时缺失了小括号和分号
具体来看,我们结合前文 Parser中 nextSym的实现,统一处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public Token matchToken (TokenType tokenType) { if (currentToken.type == tokenType) { Token tmp = currentToken; if (pos < maxLength) { pos++; currentToken = tokens.get(pos); } return tmp; } else if (tokenType == TokenType.SEMICN || tokenType == TokenType.RPARENT || tokenType == TokenType.RBRACK) { int lineNum = tokens.get(pos - 1 ).lineNum; String str = tokenType.getStr(); ErrorType errorType = mismatchErrors.get(tokenType); ErrorHandler.addError(new Error (errorType, lineNum)); return new Token (str, lineNum, tokenType); } return null ; }
语义错误处理 && 语义分析 错误处理的各个语义错误类型是相对独立的,彼此之间仅存在一定的联系,可以分别对每一种错误进行处理。在进行错误处理的过程中,我建立了栈式符号表 。
符号Symbol 我将符号的类型分为函数符号 FuncSymbol和变量符号 NumSymbol, CharSymbol,二者都继承一个父类 Symbol。
对于函数符号,我们额外记录其返回值类型以及形参的Symbol:
1 2 3 4 5 6 7 8 public class FuncSymbol extends Symbol { public enum FuncReturnType { INT, VOID, CHAR; } private FuncReturnType returnType; private ArrayList<NumSymbol> params; ... }
对于变量符号,由于其只可能是 int char 或者int char数组类型,因此我们只需要额外记录其维数。
1 2 3 4 5 6 7 8 9 10 11 java public class NumSymbol extends Symbol { private int dim; private String ifArray; } public class CharSymbol extends Symbol { private int dim; private String ifArray; }
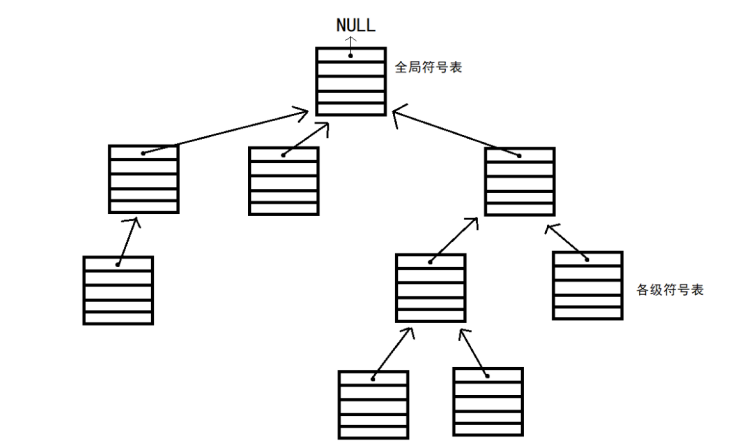
符号表SymbolTable 对于符号表,我使用栈式符号表 。在设计之初,我是想要保留一个双向的类似树结构(其实也确实实现了,但是ir生成时没有采用该符号表 ),在使用栈式符号表后保留根节点,这样就可以留下该符号表。具体来说是把下图中的单向边换成双向边:
每个符号表中,都由 TreeMap来存储具体信息,fatherSymbolTable和 sonSymbolTables维护父子间的关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class SymbolTable { private final TreeMap<String, Symbol> symbolMap; private final SymbolTable fatherSymbolTable; private final ArrayList<SymbolTable> sonSymbolTables; private final Node node; private Integer regionIndex; public SymbolTable (SymbolTable fatherSymbolTable, Node node, Integer regionIndex) { this .symbolMap = new TreeMap <>(); this .fatherSymbolTable = fatherSymbolTable; this .sonSymbolTables = new ArrayList <>(); this .node = node; this .regionIndex = regionIndex; } }
符号表栈SymbolTableStack 该类内封装有构建符号表、查符号表的各种方法,以及一个符号表栈 Stack。
该类内还有为 continue,break,return等对应错误而设置的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 public class SymbolTableStack { private Stack<SymbolTable> stack; private static TreeMap<Integer, ArrayList<Symbol>> visitResults = new TreeMap <>(); private static Integer regionIndex = 1 ; private SymbolTableStack () { this .stack = new Stack <>(); } private static SymbolTableStack instance = new SymbolTableStack (); public static SymbolTableStack getInstance () { return instance; } public static SymbolTable peek () { if (instance.stack.empty()) { return null ; } return instance.stack.peek(); } public static void stackPush (SymbolTable symbolTable) { if (!instance.stack.empty()) { peek().addSon(symbolTable); } instance.stack.push(symbolTable); } public static void nodePush (Node node) { regionIndex++; stackPush(new SymbolTable (peek(), node, regionIndex)); } public static void pop () { instance.stack.pop(); } public static void addSymbolToPeek (Symbol symbol) { peek().addSymbol(symbol); Integer index = peek().getRegionIndex(); if (!visitResults.containsKey(index)) { ArrayList<Symbol> symbols = new ArrayList <>(); symbols.add(symbol); visitResults.put(index, symbols); } else { visitResults.get(index).add(symbol); } } public static TreeMap<Integer, ArrayList<Symbol>> getVisitResults () { return visitResults; } public static void outputResult () { for (Map.Entry<Integer, ArrayList<Symbol>> entry : visitResults.entrySet()) { Integer key = entry.getKey(); ArrayList<Symbol> symbols = entry.getValue(); for (Symbol symbol : symbols) { System.out.println(key + " - " + symbol); } } } public static boolean peekHasSymbol (String name) { return peek().hasSymbol(name); } public static Symbol getSymbol (String name, SymbolType symbolType) { Symbol symbol; for (int i = instance.stack.size() - 1 ; i >= 0 ; i--) { symbol = instance.stack.get(i).getSymbol(name, symbolType); if (symbol != null ) { return symbol; } } return null ; } public static boolean stackHasSymbol (String name) { for (SymbolTable symbolTable : instance.stack) { if (symbolTable.hasSymbol(name)) { return true ; } } return false ; } public static boolean stackHasSymbolSameType (String name, SymbolType symbolType) { for (int i = instance.stack.size() - 1 ; i >= 0 ; i--) { Symbol symbol = instance.stack.get(i).getSymbol(name, null ); if (symbol != null ) { if (symbolType == SymbolType.Const) { return symbol.type.isConst(); } else { return symbol.type == symbolType; } } } return false ; } private int loopDepth = 0 ; public static boolean inLoop () { return instance.loopDepth > 0 ; } public static void enterLoop () { instance.loopDepth++; } public static void exitLoop () { instance.loopDepth = instance.loopDepth > 0 ? instance.loopDepth - 1 : 0 ; } private boolean noReturn = false ; public static boolean ifNoReturn () { return instance.noReturn; } public static void setIfReturn (boolean inVoidFunc) { instance.noReturn = inVoidFunc; } }
入栈新符号表的时机 在遍历语法树的过程中,于 MainFuncDef,FuncDef以及 Stmt的 StmtType.BLOCK场合下,调用 SymbolTableStack中封装好的方法即可入栈新的符号表,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if (type == StmtType.BLOCK) { SymbolTableStack.nodePush(this ); } public static void stackPush (SymbolTable symbolTable) { if (!instance.stack.empty()) { peek().addSon(symbolTable); } instance.stack.push(symbolTable); } public static void nodePush (Node node) { regionIndex++; stackPush(new SymbolTable (peek(), node, regionIndex)); }
添加新符号的时机 在遍历语法树的过程中,于 MainFuncDef,FuncDef以及 Stmt的 StmtType.BLOCK场合下,读取到新符号(变量、常量、函数)时调用 SymbolTableStack中封装好的方法即可。
1 2 FuncSymbol funcSymbol = new FuncSymbol (identToken.content, identToken.lineNum, this , returnType, params); SymbolTableStack.addSymbolToPeek(funcSymbol);
错误处理的逻辑 错误记录方法 在 error/ErrorUtil.java内封装有检查当前语境下错误并记录的方法。在遍历到语法树的特定位置时直接调用,即可进行错误处理。
记录错误的接口 我将所有能够生成并记录错误的方法都统一放置在了 error/ErrorUtil.java里,调用其中的方法便可(判断并)记录错误,便于后期修改。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 public static boolean checkDuplicateError (Token token) { boolean noDuplicateError = true ; if (SymbolTableStack.peekHasSymbol(token.content)) { ErrorHandler.addError(new Error (ErrorType.b, token.lineNum)); noDuplicateError = false ; } return noDuplicateError; }
具体错误的处理方法
b 类错误 - 名字重定义
对于出现错误的四条文法,读取到 ident的创建时,调用:
1 2 3 4 5 6 7 8 public static boolean checkDuplicateError (Token token) { boolean noDuplicateError = true ; if (SymbolTableStack.peekHasSymbol(token.content)) { ErrorHandler.addError(new Error (ErrorType.b, token.lineNum)); noDuplicateError = false ; } return noDuplicateError; }
c 类错误 - 未定义的名字
对于出现错误的三条文法,读取到 ident的引用时,调用:
1 2 3 4 5 6 7 8 9 public static boolean checkUndefinedError (Token token) { boolean noUndefinedError = true ; if (!SymbolTableStack.stackHasSymbol(token.content)) { ErrorHandler.addError(new Error (ErrorType.c, token.lineNum)); noUndefinedError = false ; } return noUndefinedError; }
d 类错误 - 函数参数个数不匹配
对于题目给出的文法,当 UnaryExp需要进行函数调用时,从符号表得到其形参个数,再读取其子节点的 funcRParamsNode的 expNodes的 size(),两者比较,如果不同,那就报错。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 else if (identToken != null ) { if (ErrorUtil.checkUndefinedError(identToken)) { FuncSymbol symbol = (FuncSymbol) SymbolTableStack.getSymbol(identToken.content, SymbolType.Func); if (symbol == null ) { ErrorHandler.addError(new Error (ErrorType.d, identToken.lineNum)); } else if (symbol.getParams().size() != getParaSize()) { ErrorHandler.addError(new Error (ErrorType.d, identToken.lineNum)); } else if (!checkParamsIllegal(symbol)) { ErrorHandler.addError(new Error (ErrorType.e, identToken.lineNum)); } } if (funcRParamsNode != null ) { funcRParamsNode.visit(); } }
e 类错误 - 函数参数类型不匹配
我们的变量类型只有2种:整型、一维数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 else if (identToken != null ) { if (ErrorUtil.checkUndefinedError(identToken)) { FuncSymbol symbol = (FuncSymbol) SymbolTableStack.getSymbol(identToken.content, SymbolType.Func); if (symbol == null ) { ErrorHandler.addError(new Error (ErrorType.d, identToken.lineNum)); } else if (symbol.getParams().size() != getParaSize()) { ErrorHandler.addError(new Error (ErrorType.d, identToken.lineNum)); } else if (!checkParamsIllegal(symbol)) { ErrorHandler.addError(new Error (ErrorType.e, identToken.lineNum)); } } if (funcRParamsNode != null ) { funcRParamsNode.visit(); } }
f 类错误 - 无返回值的函数存在不匹配的 return语句;g 类错误 - 有返回值的函数缺少 return语句
在 stmt的类型是 Return时,如果在函数当中但 expNode != null就报错。
h 类错误 - 不能改变常量的值
判断 <LVal>当中的 <ident>是否是常量即可。
m 类错误 - 在非循环块中使用 break 和 continue 语句
我们在符号表栈内维护了 loopCount,初始为 0,每次进入循环就加一,退出循环就减一。
在 stmt 的类型是 Break 或者 Continue 时,判断当前的 loopCount 是否为零即可,如果是,那就报错。
语义分析结果输出 1 2 3 4 5 6 7 8 9 10 public void print () { TreeMap<Integer, ArrayList<Symbol>> visitResults = SymbolTableStack.getVisitResults(); for (Map.Entry<Integer, ArrayList<Symbol>> entry : visitResults.entrySet()) { Integer key = entry.getKey(); ArrayList<Symbol> symbols = entry.getValue(); for (Symbol symbol : symbols) { IO.write(IO.IOType.VISITOR, (key + " " + symbol), true , true ); } } }
LLVM IR生成 LLVM简介 LLVM是一种三地址码,即一条LLVM语句可以表示为如下形式:
1 <运算结果> = <指令类型> <操作数1 >, <操作数2 >
观察这种指令可以发现,一条语句主要由三个要素组成:
(1)操作数(2)指令类型(3)运算结果
现在我们需要将LLVM的这种语言特性,使用Java的类设计来表达 :
在Java代码中,使用具体的类对象,来表示语句中的各个元素 。(就像语法分析中使用各种 node类来表达各种语法元素一样)具体措施是,通过遍历之前语法分析的语法树,透过结合属性翻译文法的递归下降的方式,来生成llvm的语法树 。
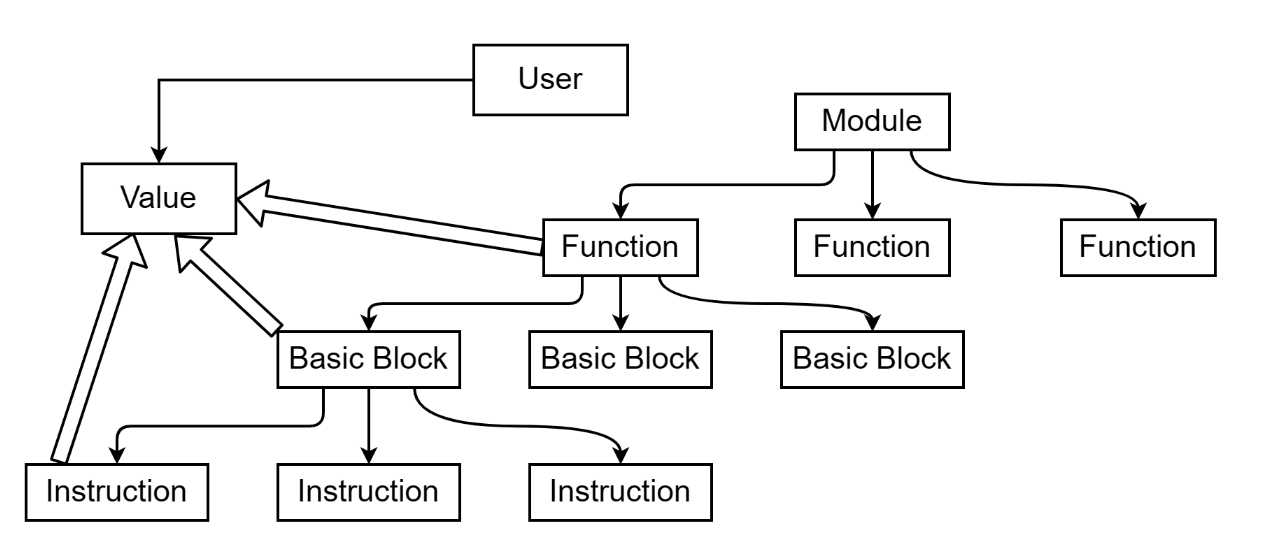
对LLVM的简单理解 我们将 llvm采用树的形式存储,根节点为 Module。
一个 module 中可以拥有两种顶层实体: Function 和 GlobalVariable
每个 Function 下都有若干基本块 BasicBlock
每个 BasicBlock下都有若干指令 instruction
在以上结构中,关键节点类的设计如下:
空心粗箭头表示类继承关系 (User和Value类也是继承关系,图应该是画错了)。
实心细箭头表示聚合关系,从而形成树结构 (例如每一个基本块 BasicBlock里有一条条指令 Instruction)。
1 <运算结果> = <指令类型> <操作数1>, <操作数2>
操作数 Value类 将操作数表示为一个类:Value,它表示能够作为操作数的对象 。
例如如下乘法语句中:
按照上面的设计,%1和 2都是Value,在Java代码中都以Value类的形式存在
操作数使用者 User类 将指令的运算结果表示为一个类:User,它表示能够作为运算结果的对象,或者说是操作数的使用者 。
例如如下乘法语句中:
按照上面的设计,%2是User,它 use了 %1和 2。%2在Java代码中以User类的形式存在
User类继承Value类 观察如下语句:
1 2 %2 = mul i32 %1, 2 %3 = add i32 %2, 3
乘法产生的 %2运算结果 在下一条加法语句中作为了操作数 。User类应该继承 Value类,这样后面的运算才能用到前面的结果。
指令 Instruction类 为每一种指令类型都创建一个 Instruction指令类,这个指令类继承 User,既用来表示运算结果,也用来表示这一条指令 。
如何理解”既用来表示运算结果,也用来表示这一条指令”?
回到 User类的例子
在代码实现当中,%2是一个 Mul指令类对象
它既表示 %2这个运算结果 :Mul extends User,这意味着这个 Mul类对象可以表示运算结果;User extends Value,这意味着这个 Mul类对象还可以作为操作数。
又表示这条语句本身 :Mul类是llvm语法树中,挂在BasicBlock下的一个节点,通过遍历语法树,并调用 toString()方法,即可从这个Mul类中取出目标代码
1 2 3 4 5 6 7 8 9 10 11 public class Mul extends ArithmeticInstruction { public Mul (String name, BasicBlock parent, Value op1, Value op2) { super (name, parent, op1, op2); } @Override public String toString () { return getArithmeticString("mul" ); } }
再例如,如下中间代码,将其翻译为Java代码,可以是:
1 2 3 4 5 6 %1 = mul i32 1 , 2 %2 = mul i32 %1 , %1 Mul mul1 = IrBuilder.buildMulInstruction(new ConstInt (1 ), new ConstInt (1 ))Mul mul2 = IrBuilder.buildMulInstruction(mul2, mul2)
常用的llvm指令罗列如下:
LLVM IR
使用方法
简介
add<result> = add <ty> <op1>, <op2>/
sub<result> = sub <ty> <op1>, <op2>/
mul<result> = mul <ty> <op1>, <op2>/
sdiv<result> = sdiv <ty> <op1>, <op2>有符号除法
srem<result> = srem <type> <op1>, <op2>有符号取余
icmp<result> = icmp <cond> <ty> <op1>, <op2>比较指令
and<result> = and <ty> <op1>, <op2>按位与
or<result> = or <ty> <op1>, <op2>按位或
call<result> = call [ret attrs] <ty> <name>(<...args>)函数调用
alloca<result> = alloca <type>分配内存
load<result> = load <ty>, ptr <pointer>读取内存
storestore <ty> <value>, ptr <pointer>写内存
getelementptr<result> = getelementptr <ty>, ptr <ptrval>{, <ty> <idx>}*计算目标元素的位置(数组部分会单独详细说明)
phi<result> = phi [fast-math-flags] <ty> [<val0>, <label0>], .../
zext..to<result> = zext <ty> <value> to <ty2>将 ty 的 value 的 type 扩充为 ty2(zero extend)
trunc..to<result> = trunc <ty> <value> to <ty2>将 ty 的 value 的 type 缩减为 ty2(truncate)
brbr i1 <cond>, label <iftrue>, label <iffalse> br label <dest>改变控制流
retret <type> <value> , ret void退出当前函数,并返回值
我在 LLVM IR 当中,给每条指令都写了一个类(Binary 指的是诸如 add sub mul 这样的二元指令),为了方便我对每种类型的指令进行管理和输出。
特殊的Value类:Function和BasicBlock类 Function和 BasicBlock类也可以作为操作数。
例如调用指令:<result> = call [ret attrs] <ty> <fnptrval>(<function args>)的实现上,我们直接将function作为了一个操作数,用来构建Call指令。
1 2 3 4 5 6 7 8 9 10 11 Function function = (Function) IrSymbolTableStack.getSymbol(identToken.content); assert function != null ; ArrayList<Value> argRValues = new ArrayList <>(); IrFactory.synValue = IrBuilder.buildCallInstruction(function, argRValues, IrFactory.curBlock); if (IrFactory.synValue.getType() instanceof CharType) { if (IrFactory.synValue instanceof ConstChar) { IrFactory.synValue = new ConstInt (32 , ((ConstChar) IrFactory.synValue).getValue()); } else { IrFactory.synValue = IrBuilder.buildZextInstruction(IrFactory.synValue, IrFactory.curBlock); } }
根节点:Module类 如同编译单元一样的存在,LLVM IR 文件的基本单位称为 module,我们的实验只有单 module。
内存 SSA llvm 是 SSA 形式的,但是在没有经过 mem2reg 的时候,SSA 是内存形式的,也就是说,对于每个变量,只要在定义他的时候,为他在内存中划分空间存入,在使用他的时候在取出来,这样就可以达到 SSA 的效果。这是因为 SSA 只要求我们不能改变一个已经定义的值,改变内存的内容显然并不违法 SSA。
这会导致当我们提到(也就是查询)一个局部变量的时候,其实是从符号表中取出来的是它的指针,这个过程一般发生在 LVal。一般我们会对变量干两件事情,读变量 和写变量 和做实参 。对于读变量,一般发生在 LVal 作为 PrimaryExp 的时候发生,此时需要在 PrimaryExp 中对其进行 Load,而写变量一般发生在 LVal 在 AssignStmt 和 InStmt 中,只需要用 Store 将其写入即可。做实参要单独挑出来讲,是因为它的逻辑是与 C 需要保持一致的,他是有指针类型的,这就要求我们对他进行单独的处理。这就是内存式 SSA 的基本逻辑。
符号表 正如前面所述,因为 LLVM IR 是 SSA 形式的,所以符号表中存的内容也和 C 中理解并不相同,比如说对于
在 C 中,我们会认为 a 在符号表中是一个 int,但是在 llvm 中,为了满足 SSA ,所以在符号表中,a 中对应的是一个指向 int 的指针,如果想要获得 a 中的内容,那么就需要使用一个 load 指令 。这就造成了某种逻辑的不一致性。更可悲的是,C 中还有 const 的概念。
1 2 3 4 5 f() { const a = 3 ; int b[a] = {1 , 2 , 3 }; }
是不是可以直接也用一个指针去存他,然后用一个 load 访存呢?大概是不行的,因为下面那个语句会用到 alloca,虽然我不确定 alloca 是否可以动态分配,但是如果是下面这种,就肯定不行了
1 2 3 4 5 6 const a = 3 ;int b[a] = {1 , 2 , 3 };f() { }
在全局部分是没有办法使用 load 指令的,尤其是我们一般面对上面的情况,会要求求出 b 的维度信息,如果维度信息不是 3 ,而是一个 load,显然就无法求出了,这就导致面对这种情况,我们必须存一个常量到符号表中,这就更要求我们在解析的时候,知道我么你啥时候存的是常量,啥时候存的是指针,这需要额外的继承属性(也是最重要的继承属性)canCalValueDown ,其实这个属性意味着一种 “常量读” 。
符号的定义 符号的定义本质是填写符号表和定义,我本来打算总结起来再写,但是感觉太冗杂了,很难理出一个头绪,所以就变成了罗列。
全局单常量 如果是一个单常量,那么只需要把 ConstInitVal 求解出来,会得到一个 int ,然后在符号表中,只需要存储一个 ConstInt 就可以了。
局部单常量 与全局单常量相同,依然是将 ConstInt 存入到符号表中,并没有任何问题。
全局常量数组 对于常量数组的初始值,我们要求是可以在编译器求值的,所以它的每个元素的初始值一定是可以被求值的,当我们求出来它的值以后,没有办法直接在符号表中存入它的值,这是因为我们会进行类似于变量的访问:
1 2 3 4 5 6 7 8 const int a[2 ] = {1 , 2 };int main () { int i = 2 ; a[i]; return 0 ; }
这样我们是没有办法在编译时就求出 a[i] 的,所以 a 必须提供变量访问形式,这就要求他必须被当成一个全局变量,所以他确实是一个全局变量,我们在符号表中存入的其实是一个全局变量,因为在 llvm 中,全局变量本质是一个指向其内容的指针,所以其实符号表中存入的是一个指针。但是也需要注意的是,其实符号表中 a 这个东西对应了两个 Value ,一个是 GlobalVariable ,另一个是 GlobalVariable.getInitValue() 获得的 ConstArray ,这样是极其有必要的,因为对于这种情况
1 2 3 4 5 6 7 8 const int a[2 ] = {1 , 2 };const int b = a[1 ];int main () { int i = 2 ; a[i]; return 0 ; }
b 的初始值没法使用 load 访问,所以只能用常量形式获得,所以依然是需要 ConstArray 的。
局部常量数组 局部常量数组与全局常量数组类似,因为它也具有“变量”的访问形式,所以也不能仅仅在符号表中存入一个 ConstArray,而是需要利用 Alloca 分配一块内存,然后利用 gep, store (这么看比全局常量数组还有麻烦一些)将这片内存填写成正确的值。同时依然需要注意,就是我们还是需要在 Alloca 里面存入一个 ConstArray 的,这是因为我们依然需要像一个“常量”一样读取这个局部常量数组,比如说在一些常量初始化或者维度信息方面,所以还是需要存入 ConstArray 的。
全局单变量 需要当成一个 GlobalVariable 处理,这是因为必须给这个单变量开辟空间,这是因为我们有可能修改这个值。
全局变量数组 也需要当成一个 GlobalVariable 处理,似乎这里保证了初始值一定是常量。
全局变量声明中指定的初值表达式必须是常量表达式。
局部单变量 用 Alloca 处理,最后在符号表中存入的是一个指针。
局部变量数组 用 Alloca 处理,但是此时的 Alloca 是不需要像局部常量数组一样在里面存储一个 ConstArray 的,这是因为第一没有意义,第二不一定能办到。
符号的使用 写变量 写一个变量一般都是对于 LVal 进行操作,并不是可以写内存中的所有东西,这是因为常量是不允许写操作的,所以对于 LVal 获得的东西一定是一个指针(LVal 的本质就是在符号表中按照符号查询出对应的 Value ),然后利用 Store 指令就可以将内容写入,“写变量”这个过程本身十分简单。
比较复杂的是如何处理 LVal ,首先需要明白,对于 LVal.builIr 可以将其分为两类,一类是 canCalValue ,也就是常量形式的读(显然没有常量写),另外就是没有办法常量读的 build,对于第二种情况,除了在符号表中找到找到指针,对于数组指针,还涉及一些 gep 操作以找到正确的数组元素。
读变量 读变量用于表达式 当一个 LVal 用于表达式的时候(也就是参与运算的时候),可以分成两个情况讨论,如果是一个常量,那么就直接用就行了;如果是一个指针,那么就需要将其 Load 出来使用。
读变量用于实参 实参和表达式计算不同在于,他可能是一个指针。而因为 C 的指针与 llvm 是不同的,比如说同样一个一维数组 a[2] ,在 C 中为 int* ,而在 llvm 中,却是 [2 x i32]* 。而当参数为 int a[] 的时候,又要求 llvm 划为 int*,这就说需要控制 gep 的数量进行降维,同时对于为指针的变量,也不能一味的 load,这样有可能将原本的指针实参给 Load 出一个整型来。
短路求值 对于短路求值,并不是一件可有可无的事情,因为对于
如果没有短路求值,那么 f() 就会被指令,如果 f() 是一个有副作用的函数(也就是对内存写了),那么就会导致 bug 的出现,所以短路求值是必要的。
实现短路求值就是将
变成
这样的结构,将
变成
1 2 3 4 5 6 7 8 9 if (cond1) { } else { if (cond2) { } else { } }
对于多个条件,只要确定好优先级,递归处理即可。
控制结构 控制结构就是通过制造 BasicBlock 来对数据流进行控制。
分支 ConditionNode 有两种可能,有无 else 决定了到底是 2 个 BasicBlock 或者是 3 个 BasicBlock。对于没有 else 的分支结构,只用一个三参数的 Br 就可以解决,对于有 else 的结构,只需要将 Br 的 falseBlock 调整为 else 对应的块即可。
循环 需要制作出 3 个块,分别为 condBlock, bodyBlock, nextBlock ,其中 condBlock 选择跳转到 bodyBlock 或者是 nextBlock (这个部分由 LOrExp, LAndExp 自动完成 ),bodyBlock 会无条件跳转到 condBlock。
Break & Continue & Return 这些指令面对的最大问题是为了满足基本块的定义,与这些指令所处同一基本块并位于这些指令之后的指令不应该得到翻译。我们可以直接做一个新的块,让其后的指令都依附与这个块,而入口块并没有到达这个块的方式,这样就完成了对其后指令的忽略。
此外,break, continue 都需要确定跳转的目标,break 会跳转到 nextBlock ,而 continue 会跳转到 condBlock ,但是因为循环存在嵌套结构,所以不同层的 break, continue 需要跳转到不同的层。所以在全局用一个栈维护该结构,如下所示
1 2 3 4 5 6 7 8 9 10 11 public static Stack<BasicBlock> loopEndBlockStack = new Stack <>(); public static Stack<BasicBlock> endBlockStack = new Stack <>();
在循环的时候,进行出入栈操作
1 2 3 4 5 6 7 8 IrFactory.loopEndBlockStack.push(loopEndBlock); IrFactory.endBlockStack.push(endBlock); ((StmtNode) nodes.get(nodePos)).setStmtReturnType(this .stmtReturnType); nodes.get(nodePos).buildIr(); IrFactory.loopEndBlockStack.pop(); IrFactory.endBlockStack.pop();
在 break 中:
1 2 IrBuilder.buildBrInstruction(IrFactory.endBlockStack.peek(), IrFactory.curBlock);
在 continue 中
1 2 IrBuilder.buildBrInstruction(IrFactory.loopEndBlockStack.peek(), IrFactory.curBlock);
具体架构设计 IrBuilder类:指令的工厂 IrBuilder类是中间代码的入口,同时也封装有构建 llvm元素的工厂模式方法 。
举例来说,我们现在正要取出一个指针类型变量所指空间中的内容,可以构建一条 Load指令(当然如果是数组就需要GEP指令了),并将其插入当前所处的基本块。可以如此做:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Value fParamValue = IrBuilder.buildLoadInstruction(lvalValue, IrFactory.curBlock); if (expNode == null ) { IrFactory.synValue = fParamValue; } else { expNode.buildIr(); if (IrFactory.synValue.getType() instanceof CharType) { if (IrFactory.synValue instanceof ConstChar) { IrFactory.synValue = new ConstInt (32 , ((ConstChar) IrFactory.synValue).getValue()); } else { IrFactory.synValue = IrBuilder.buildZextInstruction(IrFactory.synValue, IrFactory.curBlock); } } Value indexValue = IrFactory.synValue; Value ptrVal = IrBuilder.buildGetElementPtrInstruction(fParamValue, indexValue, IrFactory.curBlock); if (IrUtil.getPointingTypeOfPointer(fParamValue) instanceof ArrayType) { ptrVal = IrBuilder.buildRankDownInstruction(ptrVal, IrFactory.curBlock); } IrFactory.synValue = ptrVal; public static Load buildLoadInstruction (Value pointer, BasicBlock parent) { Load load = new Load (getName(), parent, pointer); parent.addInstruction(load); return load; }
IrFactory:递归下降的上下文信息 刚刚我们提到,要进行基于属性翻译文法的递归下降。既然是属性翻译文法,势必涉及到综合属性(synthesized attribute)的向上传递 ,以及继承属性(inherited attribute)的向下传递 。
得益于递归下降的方法,我们可以直接在 node类内,通过父子 node间直接调用对方的相关 setter或者 getter来粗暴地实现信息传递。
但如果我们传递的链条很长呢?譬如我们在一个 LVal内的信息,要经过好长好长的路,才能抵达真正需要该信息的 ConstExp,这时候如果还要写那么多 setter,未免也过于笨。
考虑到只有综合属性会出现这种长线的传递,我们可以在 Irc里直接记录全局的,正在传递的综合属性(们):
1 2 3 4 5 6 7 8 9 10 11 12 13 public static ArrayList<Value> synValueArray = null ;public static Value synValue = null ;public static int synInt = -114514 ;
中间代码的构建过程,是字面意义上拆东墙建西墙的过程,即在根据文法递归下降 扫描语法分析结果的同时,在另一边逐步(用动作符号)搭建起另一个 llvm的体系。
既然是同步在扫描两个体系,就应当有两组指针来记录扫描进度。语法分析的扫描进度(由递归下降保证外,还有当前是否在扫描常量表达式,是否在扫描函数实参,是否正在经历循环),llvm的构建进度(即当前在搭建哪个函数,哪个基本块,)都应当得到记录 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public static BasicBlock curBlock = null ; public static Function curFunction = null ; public static boolean isBuildingConstExp = false ; public static boolean isBuildingGlobalInit = false ; public static boolean isBuildingPointerRParam = false ; public static Stack<BasicBlock> loopEndBlockStack = new Stack <>(); public static Stack<BasicBlock> endBlockStack = new Stack <>();
llvm元素llvm元素主要放置在 ir/values内。
该类主要存储了 llvm体系下,该元素的要素及其相应的 getter和 setter。
此外,所有 llvm元素都实现了 buildMips()方法(及辅助方法),用于后续构建 mips体系。
因此,llvm元素类是贯穿了 llvm初步生成,中端的 mem2reg重构,mips初步生成
举例来说,我们在基本块 BasicBlock类内,会记录这样的一些信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 private final HashSet<BasicBlock> preBlocks = new HashSet <>(); private final HashSet<BasicBlock> sucBlocks = new HashSet <>(); private final ArrayList<BasicBlock> domers = new ArrayList <>(); private final ArrayList<BasicBlock> idomees = new ArrayList <>(); private BasicBlock Idomer; private int domLevel; private final HashSet<BasicBlock> dominanceFrontier = new HashSet <>(); public ArrayList<BasicBlock> getDomers () { return domers; } public boolean isDominating (BasicBlock other) { return other.domers.contains(this ); } public ArrayList<BasicBlock> getIdomees () { return idomees; } public void setIdomer (BasicBlock idomer) { Idomer = idomer; } public void setDomLevel (int domLevel) { this .domLevel = domLevel; } public int getDomLevel () { return domLevel; } public HashSet<BasicBlock> getDominanceFrontier () { return dominanceFrontier; } public BasicBlock getIdomer () { return Idomer; } private Loop loop = null ; public int getLoopDepth () { if (loop == null ) { return 0 ; } return loop.getLoopDepth(); } public void setLoop (Loop loop) { this .loop = loop; } public Loop getLoop () { return loop; }
再议 SSA 现在再看回SSA:
当涉及到分支语句时,SSA会遇到一些问题,以下面这个循环为例:
1 2 3 4 5 6 7 8 9 10 11 int main () { int i = 0 ; i = getint(); int a = 1 ; a = getint(); for (; i < 10 ; i = i + 1 ){ i = i + 2 ; a = a + 3 ; } return 0 ; }
我们会发现,对于循环的归纳变量,其注定会有两处赋值。因此同样对于 i和 a,我们需要再来一个 i1和 a1来放置这第二个赋值。
那么问题来了,在 i1和 a1的汇聚点,到底该采取哪个赋值?这时候就必须用到 phi指令。
phi 指令这个指令能够根据进入当前基本块之前执行的是哪一个基本块的代码来选择一个变量的值。
1 <result> = phi <ty> [<val0 >, <label 0 >], [<val1 >, <label 1 >] ...
有了 phi,我们就可以写出代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 define dso_local i32 @main () {b0 : %i3 = call i32 @getint () %i7 = call i32 @getint () br label %b9 b9 : %p25 = phi i32 [ %i3 , %b0 ], [ %i16 , %b11 ] %p24 = phi i32 [ %i7 , %b0 ], [ %i19 , %b11 ] %i14 = icmp slt i32 %p25 , 10 br i1 %i14 , label %b10 , label %b12 b10 : %i19 = add i32 %p24 , 2 %i22 = add i32 %p25 , 3 br label %b11 b11 : %i16 = add i32 %i22 , 1 br label %b9 b12 : ret i32 0 }
但实际上,phi指令的构建有亿点点复杂,这也太难写了!如果有一个能够摆脱SSA限制的办法就好了。
这就要用到我们之前提到的内存SSA:
这种生成存取内存的 llvm有四个特点:
每个局部变量都变为了栈上分配的空间(变量在符号表中存的其实是其 alloca 指令)
每次对局部变量的读都变成了从内存空间中的一次读(在 LValNode中实现,这也是为什么这里是指针的故乡之一!)
每次对局部变量的写都变成了对内存的一次写(每次更新一个变量的值都变成了通过 store 对变量所在内存的写)
获取局部变量的地址等价于获取内存的地址
需要进行的主要操作有:
ConstExp的处理与“后门”常量传播 在我们的文法当中,有这样的声明:
常量表达式 ConstExp
ConstExp -> AddExp 中使用的 ident 必须是常量
何为常量?即能够在编译阶段就确定值的量,包括了常量标识符与立即数。对于常量,我们可以在编译阶段就计算出常量表达式的值,以及将常量标识符替换为其值 。
为此,我们在 IrFactory里设置有字段,在 Exp系的 buildIr内,构建常量时的分类讨论的方式有所不同,且由于能够计算出int类型具体值,我们只需要进行 synInt综合属性的传递。
常量分为数组常量和非数组常量,其行为有所不同:
int常量
数组常量
是否在llvm代码中显式声明
否
与普通数组变量一致,采用alloca,store
在 ConstExp下
直接求出int, char值
直接求出指定元素的int值
非 ConstExp下
直接求出int, char值
与普通数组变量一致,采用gep,load
Mips 生成 在llvm中,我们已经将源代码转换成了很接近中间代码的形式了:我们划分并生成了基本块,生成了几乎能一等一转化为mips的llvm指令 。因此在目标代码的初步 生成的过程中,我们的关注点主要在于存储管理、指令的等价翻译 。
MipsBuilder:指令的工厂类 在MipsBuilder中封装有构建各种指令、构建操作数的工厂模式方法。
例如构建一条 add指令并加入指定的 MipsBlock:
1 2 3 4 5 6 7 8 9 10 public static MipsBinary buildBinary (MipsBinary.BinaryType type, MipsOperand dst, MipsOperand src1, MipsOperand src2, BasicBlock irBlock) { MipsBinary binary = new MipsBinary (type, dst, src1, src2); MipsFactory.irBlock2MipsBlock(irBlock).addInstruction(binary); return binary; }
MipsFactory:记录 llvm成分到 mips成分的映射 我们是在llvm的成分类中进行的mips生成,因此需要将llvm成分与mips成分进行映射。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static MipsFunction irFunction2MipsFunction (Function irFunction) { return functionMap.get(irFunction); } public static MipsBlock irBlock2MipsBlock (BasicBlock irBlock) { return blockMap.get(irBlock); } public static MipsOperand irValue2MipsOp (Value irValue) { return opMap.get(irValue); }
llvm的成分类:mips生成的主要场所通过遍历 llvm的树形结构来生成 mips,遍历在 ir/values下的各个value类进行,他们都实现了父类 Value的 buildMips()方法。
backend/instructions: Mips指令类指令类都继承了 MipsInstruction类,该类内有 src操作数和 dst操作数的相应管理方法,包括 use,def的记录,用于活跃变量分析,以及后续寄存器分配时,对虚拟寄存器进行查询、替换 。
backend/operands: 操作数类该包内的类均可以作为 mips指令的操作数,具体来说有立即数、虚拟寄存器、物理寄存器、标签。
物理寄存器的相关配置在 RegType枚举类中,记录了物理寄存器的编号、名称、何者需要在函数调用时保存、何者能够作为全局寄存器分配等信息。
构建流程 带有虚拟寄存器的mips的总体构建流程如下:
构建.data段 构建.data段主要是在翻译 llvm的全局变量元素 GlobalVariable。
先前在 llvm生成过程中,我们将需要 printf输出的字符串重新分配为了全局常量字符串,因此这里全局变量共有三类:字符串、int变量、int数组。依次构建 mipsGlobalVariable,然后加入 MipsModule即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Override public void buildMips () { MipsGlobalVariable mipsGlobalVariable = null ; if (initValue == null ) { System.out.println("[buildMips] GlobalVariable:initValue == null" ); } else if (initValue instanceof ZeroInitializer) { mipsGlobalVariable = new MipsGlobalVariable (getName(), initValue.getType().getSize()); } else if (initValue instanceof ConstString) { mipsGlobalVariable = new MipsGlobalVariable (getName(), ((ConstString) initValue).getContent()); } else if (initValue instanceof ConstInt) { mipsGlobalVariable = new MipsGlobalVariable (getName(), new ArrayList <>() {{ add(((ConstInt) initValue).getValue()); }}, MipsGlobalVariable.GVType.Int); } else if (initValue instanceof ConstChar) { mipsGlobalVariable = new MipsGlobalVariable (getName(), new ArrayList <>() {{ add(((ConstChar) initValue).getValue()); }}, MipsGlobalVariable.GVType.Char); } else if (initValue instanceof ConstArray) { ArrayList<Integer> inits = new ArrayList <>(); if (((ConstArray) initValue).getElements().get(0 ).getType() instanceof IntType) { for (Constant element : ((ConstArray) initValue).getElements()) { inits.add(((ConstInt) element).getValue()); } mipsGlobalVariable = new MipsGlobalVariable (getName(), inits, MipsGlobalVariable.GVType.Int); } else { for (Constant element : ((ConstArray) initValue).getElements()) { inits.add(((ConstChar) element).getValue()); } mipsGlobalVariable = new MipsGlobalVariable (getName(), inits, MipsGlobalVariable.GVType.Char); } } MipsModule.addGlobalVariable(mipsGlobalVariable); }
为所有Block和Function创建Mips对象,并映射到llvm的相应对象 没有太多可说的,作用主要是方便在后续遍历语句时,能够方便地引用函数和基本块(用于call、br等llvm指令的翻译)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private void mapFunctionBlockIr2Mips () { for (Function irFunction : functions) { MipsFunction mipsFunction = new MipsFunction (irFunction.getName(), irFunction.isLibFunc()); MipsFactory.addFunctionMapping(irFunction, mipsFunction); MipsModule.addFunction(mipsFunction); ArrayList<BasicBlock> blocks = irFunction.getBasicBlocks(); for (BasicBlock irBlock : blocks) { MipsBlock mipsBlock = new MipsBlock (irBlock.getName(), irBlock.getLoopDepth()); MipsFactory.addBlockMapping(irBlock, mipsBlock); } for (BasicBlock irBlock : blocks) { MipsBlock mipsBlock = MipsFactory.irBlock2MipsBlock(irBlock); for (BasicBlock irPreBlock : irBlock.getPreBlocks()) { mipsBlock.addPreBlock(MipsFactory.irBlock2MipsBlock(irPreBlock)); } } } }
遍历 llvm的树形结构 依序遍历 llvm的所有函数、所有基本块、所有指令,进行翻译。
具体构建难点 实际上,将 LLVM指令挨个翻译成 MIPS指令并不困难,我们重点讲一下翻译成 Mips时函数调用的部分,这是一大难点,至于寄存器分配则放到优化部分详述。
Call:参数传递 Call的作用是调用函数,理所当然地,在mips中需要我们手动进行实参的传递,同时记录 MipsCall指令对于寄存器的修改(即def)。
对于前四个参数,保存在 a0-a3里即可。对于更多的参数,需要保存在栈上。
调用函数在调用者处的准备工作,都由Call进行翻译。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 @Override public void buildMips () { MipsBuilder.buildComment(this .toString(), getParent()); MipsBlock mipsBlock = MipsFactory.irBlock2MipsBlock(getParent()); MipsFunction mipsFunction = MipsFactory.irFunction2MipsFunction(function); MipsInstruction call; if (function.isLibFunc()) { call = new MipsMacro (mipsFunction.getName()); call.addDefReg(MipsRealReg.V0); } else { call = new MipsCall (mipsFunction); } int argc = getArgs().size(); for (int i = 0 ; i < argc; i++) { Value irArg = getArgs().get(i); MipsOperand src; if (i < 4 ) { src = MipsBuilder.buildOperand(irArg, true , MipsFactory.curIrFunction, getParent()); MipsMove move = MipsBuilder.buildMove(new MipsRealReg ("a" + i), src, getParent()); call.addUseReg(move.getDst()); } else { boolean isByte = irArg.getType() instanceof CharType; src = MipsBuilder.buildOperand(irArg, false , MipsFactory.curIrFunction, getParent()); MipsImm offsetOperand = new MipsImm (-(argc - i) * 4 ); MipsBuilder.buildStore(src, MipsRealReg.SP, offsetOperand, getParent(), isByte); } } if (argc > 4 ) { MipsOperand offsetOperand = MipsBuilder.buildImmOperand(4 * (argc - 4 ), true , MipsFactory.curIrFunction, getParent()); MipsBuilder.buildBinary(MipsBinary.BinaryType.SUBU, MipsRealReg.SP, MipsRealReg.SP, offsetOperand, getParent()); } mipsBlock.addInstruction(call); if (argc > 4 ) { MipsOperand offsetOperand = MipsBuilder.buildImmOperand(4 * (argc - 4 ), true , MipsFactory.curIrFunction, getParent()); MipsBuilder.buildBinary(MipsBinary.BinaryType.ADDU, MipsRealReg.SP, MipsRealReg.SP, offsetOperand, getParent()); } for (int i = 0 ; i < 4 ; i++) { call.addDefReg(new MipsRealReg ("a" + i)); } if (!function.isLibFunc()) { call.addDefReg(MipsRealReg.RA); } ValueType returnType = function.getReturnType(); call.addDefReg(MipsRealReg.V0); if (!(returnType instanceof VoidType)) { MipsOperand dst = MipsBuilder.buildOperand(this , false , MipsFactory.curIrFunction, getParent()); MipsBuilder.buildMove(dst, MipsRealReg.V0, getParent()); } }
MipsFunction:保存现场 MipsFunction是Mips函数对象。
在与Call的关系中,MipsFunction是被调用的一方,由MipsFunction负责保存现场。
如下方法能够记录在本函数内有改动(def)的寄存器,同时计算栈帧大小。这些寄存器在返回调用者后可能有改变,需要保存在栈帧内。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public void rebuildStack () { for (MipsBlock block : blocks) { for (MipsInstruction instruction : block.getInstructions()) { for (MipsOperand defReg : instruction.getDefRegs()) { if (defReg instanceof MipsRealReg) { RegType regType = ((MipsRealReg) defReg).getType(); if (RegType.regsNeedProtection.contains(regType)) { regsNeedSaving.add(regType); } } else { System.out.println("[MipsFunction] defReg中混入了非物理寄存器!" ); } } } } int stackRegSize = 4 * regsNeedSaving.size(); System.out.println(stackRegSize); for (RegType regType : regsNeedSaving) { System.out.println(regType); } totalStackSize = stackRegSize + allocaSize; for (MipsImm argOffset : argOffsets) { int newOffset = argOffset.getValue() + totalStackSize; argOffset.setValue(newOffset); } }
保存现场的具体代码则直接放在了 MipsFunction的打印处,实际上没有加入指令序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Override public String toString () { if (isLibFunc) { return "" ; } StringBuilder sb = new StringBuilder (); sb.append(name).append(":\n" ); if (!name.equals("main" )) { int stackOffset = -4 ; for (RegType regType : regsNeedSaving) { sb.append("\t" ).append("sw\t" ).append(regType).append(",\t" ) .append(stackOffset).append("($sp)\n" ); stackOffset -= 4 ; } } if (totalStackSize != 0 ) { sb.append("\taddiu\t$sp,\t$sp,\t" ).append(-totalStackSize).append("\n" ); } for (MipsBlock block : blocks) { sb.append(block); } return sb.toString(); }
MipsRet:恢复现场 MipsRet是Mips的返回指令对象,由llvm的Ret指令直接翻译而来。
Ret对象会记录其所属的MipsFunction,以方便地取用寄存器的保存信息。
同样地,恢复现场的具体代码则直接放在了 MipsRet的打印处,实际上没有加入指令序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Override public String toString () { StringBuilder sb = new StringBuilder (); int stackSize = function.getTotalStackSize(); if (stackSize != 0 ) { sb.append("addiu\t$sp, \t$sp,\t" ).append(stackSize).append("\n" ); } if (function.getName().equals("main" )) { sb.append("\tli\t$v0,\t10\n" ); sb.append("\tsyscall\n\n" ); } else { int stackOffset = -4 ; for (RegType regType : function.getRegsNeedSaving()) { sb.append("\t" ).append("lw\t" ).append(regType).append(",\t" ).append(stackOffset).append("($sp)\n" ); stackOffset -= 4 ; } sb.append("\tjr\t$ra\n" ); } return sb.toString(); }
代码优化 总论 优化分为两类,一类是分析型优化,这种类型的优化并不会改变 llvm ir 的结构,所以也不会有实际的优化效果,但是它们分析出来的信息,会去指导加工型优化的进行。另一种是加工型优化,这种优化会真正改变 llvm ir & mips 的结构,达到优化的目的。
控制流图构建 在构建控制流图之前,我们先进行简单的死代码删除:
该部分会删除所有 ret指令后的代码。
这其实是为了解决在debug时发现的一个严重错误:为了确保在构建控制流图时,不会产生奇怪的后继,从而导致控制流图构建错误、phi指令报错 。
在遇到 ret指令后,删除所有指令即可。
1 2 3 4 5 6 7 8 9 10 11 12 public static void deadCodeEmit (BasicBlock block) { LinkedList<Instruction> instructions = new LinkedList <>(block.getInstructions()); boolean flag = false ; for (Instruction instruction : instructions) { if (flag) { instruction.dropAllOperands(); instruction.eraseFromParent(); } else if (instruction instanceof Ret || instruction instanceof Br) { flag = true ; } } }
支配分析
[!IMPORTANT]
在进行很多分析之前,都需要进行支配分析,这是因为支配树会提供很多的支配流信息,尤其是数据是怎样在数据块中流动,哪些数据必然从这个块流入另一个块,可以说,支配信息是对于 CFG 图的一种高度凝练的表达。
在求解支配树的时候,分为两步,第一步首先支配者和被支配者,这是一个不动点问题,利用的公式是
$$
[!IMPORTANT]
需要一直求解到不发生变化为止。
第二步是计算支配边界,构造支配树,支配树是比原来的支配图更加直观而且“强”的条件,我们在优化中一般也是使用支配树的信息条件。所谓支配边界,就是恰好不被支配的一个块。
需要强调,支配树不仅应用在编译领域,这是一个很常见的图论算法,所以可以在网上找到详实的资料,所以对于算法问题就不赘述。
支配分析基于 CFG图会被用在 LoopInfoAnalyze, mem2reg,所以只要 CFG 发生改变,就会需要重新分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 public static void passDominanceInfo (Function function) { BasicBlock entryBlock = function.getHeadBlock(); int blockNum = function.getBasicBlocks().size(); ArrayList<BitSet> domers = new ArrayList <>(blockNum); ArrayList<BasicBlock> blocks = function.getBasicBlocks(); int index = 0 ; for (BasicBlock block : blocks) { domers.add(new BitSet ()); if (block == entryBlock) { domers.get(index).set(index); } else { domers.get(index).set(0 , blockNum); } index++; } boolean changed = true ; while (changed) { changed = false ; index = 0 ; for (BasicBlock curBlock : blocks) { if (curBlock != entryBlock) { BitSet temp = new BitSet (); temp.set(0 , blockNum); for (BasicBlock preBlock : curBlock.getPreBlocks()) { int preIndex = blocks.indexOf(preBlock); temp.and(domers.get(preIndex)); } temp.set(index); if (!temp.equals(domers.get(index))) { domers.get(index).clear(); domers.get(index).or(temp); changed = true ; } } index++; } } for (int i = 0 ; i < blockNum; i++) { BasicBlock curBlock = blocks.get(i); BitSet domerInfo = domers.get(i); for (int domerIndex = domerInfo.nextSetBit(0 ); domerIndex >= 0 ; domerIndex = domerInfo.nextSetBit(domerIndex + 1 )) { BasicBlock domerBlock = blocks.get(domerIndex); curBlock.getDomers().add(domerBlock); } } for (BasicBlock curBlock : blocks) { for (BasicBlock maybeIdomerBlock : curBlock.getDomers()) { if (maybeIdomerBlock != curBlock) { boolean isIdom = true ; for (BasicBlock domerBlock : curBlock.getDomers()) { if (domerBlock != curBlock && domerBlock != maybeIdomerBlock && domerBlock.getDomers().contains(maybeIdomerBlock)) { isIdom = false ; break ; } } if (isIdom) { curBlock.setIdomer(maybeIdomerBlock); maybeIdomerBlock.getIdomees().add(curBlock); break ; } } } } passDominanceLevel(entryBlock, 0 ); }
函数调用分析
[!IMPORTANT]
如果在调用者和被调用者之间构建一条有向边,那么就可以构建一个函数调用图,函数调用关系主要是为了后面的副作用分析,无用函数删除做准备。在实际应用中,一般不会单独作为一个 pass ,这是因为这个用的很多,基本上是随用随做。
因为 SysY并不支持函数声明,所以其实不会出现循环递归或者其他的阴间情况,这无疑对后面是一个好消息。
副作用分析
[!IMPORTANT]
所谓的副作用(SideEffect),其实没有一个明确的概念,大概就是我们不喜欢的作用,就会被叫做副作用。在中端的副作用,指的是某个指令或者函数,会不会对内存或者 IO 造成影响,如果不会,那么就是没有副作用的。
没有副作用的东西很良好,因为他们造成的唯一影响只能通过返回值,所以如果返回值没有用到,那么这个东西就可以去掉了。不仅仅是去掉这么暴力,如果没有副作用,相当于有了一个很“强”的条件保证,我们对于某些优化的进行会变得更加自信,比如说一个函数如果没有副作用,我们就可以直接把他当成一条指令处理,对于
1 2 %i1 = call i32 f(%a1 )%i2 = call i32 f(%a1 )
[!IMPORTANT]
我们可以直接判断 i1 == i2 是很好的东西。
进行副作用分析的时候,需要先构建一个函数调用关系图,这是因为有的函数本身并不会造成副作用,但是他调用的函数就会有副作用,导致调用这个函数也会有副作用。
我们一般认为这几个东西有副作用
Mem2Reg 在 LLVM生成部分中,我们已经了解了SSA的两种形式:走访存后门的SSA,和真正能提高效率的采取 phi的真SSA 。
在这一步,我们将进行如下两项工作以重构llvm代码:
后门SSA中,繁复 alloca,store,load三件套的彻底铲除优化。
phi指令的插入与变量的重命名。
[!IMPORTANT]
一个基本块的开始需要插入一个变量的 phi 节点的条件,是这个基本块是这个变量某个定义的支配边界。这个操作需要迭代,事实上就只需要建立一个队列,每次取出队首,计算其支配边界,并把新算出的支配边界插入到队列的末尾。
注意,这时的 phi 节点还是空的,即只有左值没有右值。
简单的运算强度削弱 即对于 a * 0, 0 / a, a % 1, a / a这一类指令提前完成优化,避免繁复计算
Aggressive Dead Code Emit
[!IMPORTANT]
在这一步中我们认为的死代码,就是不会对程序造成影响的代码,我们可以用与“副作用分析”类似的眼光去看,所有的访存指令,return 指令,call 一个有副作用的函数,分支指令,这些东西都是有用的 ,我们不能删除,那么这些指令使用到的指令,同样也是不能删除的,以此类推,这样求出一个有用指令的闭包 ,所有不在这个指令闭包内的指令,都是死代码,是可以删除的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 private void findUsefulClosure (Instruction instruction) { if (!usefulInstrClosure.contains(instruction)) { usefulInstrClosure.add(instruction); for (Value operand : instruction.getOperands()) { if (operand instanceof Instruction) { findUsefulClosure((Instruction) operand); } } } } private void deleteDeadInstructions (Function curFunction) { usefulInstrClosure.clear(); for (BasicBlock basicBlock : curFunction.getBasicBlocks()) { for (Instruction instruction : basicBlock.getInstructions()) { if (isUseful(instruction)) { findUsefulClosure(instruction); } } } for (BasicBlock basicBlock : curFunction.getBasicBlocks()) { LinkedList<Instruction> newInstructions = new LinkedList <>(); for (Instruction instruction : basicBlock.getInstructions()) { boolean delete = false ; if (!usefulInstrClosure.contains(instruction)) { instruction.dropAllOperands(); delete = true ; } if (!delete) { newInstructions.add(instruction); } } basicBlock.setInstructions(newInstructions); } }
全局变量局部化
[!IMPORTANT]
因为全局变量的访问需要在 llvm 中访存,比较低效,所以考虑对于只被一个函数使用了的全局变量(这就没有意义是全局的了),将其移入成局部变量。
乘除法优化 对于处理器来说,执行乘除法的代价要远大于执行其他指令,而执行除法的代价又远大于乘法的代价,所以我们理想的情况是通过算术运算将除常数转化为乘法和移位指令,将乘常数转化为移位和其他指令。
乘法优化 乘法可以被优化成加法和移位操作,因为乘法的代价是 4,所以加法和移位操作最多有 3 条,那么考虑“移位-加法-移位”的组合,那么也就是可以拆出两条移位指令,那么可以枚举 32 位内由上述组合可以达到的组合,然后记录下来。在乘法运算的时候,可以按照事先准备的进行操作。
除法优化 对于任何处理器,进行除法计算所需要的时间都远远高于乘法和移位运算(当然这两者也不在一个量级上),所以我们有一种想法,就是把除法转换成乘法和移位操作,也就是
$$
具体实现则参考了教程所给论文:Division by Invariant Integers using Multiplication 。
图着色寄存器分配 首先以函数为单位,对其所有基本块进行活跃变量分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public static HashMap<MipsBlock, BlockLiveVarInfo> liveAnalysis (MipsFunction func) { HashMap<MipsBlock, BlockLiveVarInfo> liveInfoMap = new HashMap <>(); for (MipsBlock block : func.getMipsBlocks()) { BlockLiveVarInfo blockLiveInfo = new BlockLiveVarInfo (); liveInfoMap.put(block, blockLiveInfo); for (MipsInstruction instruction : block.getInstructions()) { instruction.getUseRegs().stream() .filter(MipsOperand::needsColor) .filter(use -> !blockLiveInfo.liveDef.contains(use)) .forEach(blockLiveInfo.liveUse::add); instruction.getDefRegs().stream() .filter(MipsOperand::needsColor) .forEach(blockLiveInfo.liveDef::add); } blockLiveInfo.liveIn.addAll(blockLiveInfo.liveUse); } boolean changed = true ; while (changed) { changed = false ; for (MipsBlock block : func.getMipsBlocks()) { BlockLiveVarInfo blockLiveInfo = liveInfoMap.get(block); HashSet<MipsOperand> newLiveOut = new HashSet <>(); if (block.getTrueSucBlock() != null ) { BlockLiveVarInfo sucBlockInfo = liveInfoMap.get(block.getTrueSucBlock()); newLiveOut.addAll(sucBlockInfo.liveIn); } if (block.getFalseSucBlock() != null ) { BlockLiveVarInfo sucBlockInfo = liveInfoMap.get(block.getFalseSucBlock()); newLiveOut.addAll(sucBlockInfo.liveIn); } if (!newLiveOut.equals(blockLiveInfo.liveOut)) { changed = true ; blockLiveInfo.liveOut = newLiveOut; blockLiveInfo.liveIn = new HashSet <>(blockLiveInfo.liveUse); blockLiveInfo.liveOut.stream() .filter(objOperand -> !blockLiveInfo.liveDef.contains(objOperand)) .forEach(blockLiveInfo.liveIn::add); } } } return liveInfoMap; }
基于活跃变量分析的结果,我们就可以开始图着色算法了:
主要流程如下,遍历所有函数,对于每个函数,进行活跃变量分析直至不再变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public void buildRegs () { for (MipsFunction function : mipsModule.getFunctions()) { if (function.isLibFunc()) { continue ; } curFunction = function; boolean finished = false ; while (!finished) { initStatus(); buildConflictGraph(); buildWorklist(); do { if (!simplifyList.isEmpty()) { doSimplify(); } if (!mergableMoves.isEmpty()) { coalesce(); } if (!freezeList.isEmpty()) { doFreeze(); } if (!spillList.isEmpty()) { doSelectSpill(); } } while (!(simplifyList.isEmpty() && mergableMoves.isEmpty() && freezeList.isEmpty() && spillList.isEmpty())); assignColors(function); if (spilledNodes.isEmpty()) { finished = true ; } else { try { rewriteProgram(function); } catch (Exception e) { System.out.println("[RewriteProgramException] " + e + ", function: " + function.getName()); } } } } resetRealRegState(); for (MipsFunction function1 : mipsModule.getFunctions()) { if (function1.isLibFunc()) { continue ; } function1.rebuildStack(); } }
构造冲突图(build) 本阶段的主要任务是通过数据流分析方法,计算在每条指令执行时同时活跃的临时变量,该集合的每一对临时变量两两形成一条边加入冲突图中,
构造阶段的主要工作是进行数据流分析,分为两个阶段:基本块的数据流分析,指令间的数据流分析,得到冲突图,指令冲突的条件是在变量定义处所有出口活跃的变量和定义的变量是互相冲突的,以及同一条指令的出口变量互相之间是冲突的。
简化(simplify) 进行启发式图着色,删除度数小于K(通用寄存器个数)的节点,简化冲突图,产生更多图着色机会。
具体的做法是对于一个节点m,如果它的度数小于K,那么将它从冲突图当中删除,并且将其压入栈中,以便进行后续的着色。
这样进行启发式删除之后,都会减少其他结点的度数,从而产生更多的简化的机会,并且也为之后的合并提供更多机会,这要求在这个阶段不会简化非冻结指令。
合并(coalesce) 进行保守的合并,减少最终代码的move指令。
对于move指令(例如 move $2, $3),源操作数和目的操作数实际上相同,这种情况下可以将两个节点合并,减少一条move指令的代价,但是,合并两个结点之后,两个节点的活跃范围会增加,其邻接结点的集合实际上是原来两个集合的并集,这种情况下可能会导致一些能够着色的节点变为被溢出的结点,这样就得不偿失了,因此我们给出的一种策略是在合并的时候进行判断,保证合并之后高度数(度数>=K)的结点不会增加。通过简化之后,冲突图很多节点的度数已经降低,所以这个时候合并的机会可能多于原有的冲突图。
合并的效果通常决定了整个图着色算法的质量,另外由于在进行指令选择之前需要消PHI,会在这个时候产生很多冗余的move指令,通过图着色的时候进行合并能够极大的减少冗余的move指令,这对程序性能的提升非常大。
冻结(freeze) 在进行简化和合并之后,有一些变量无法进行合并,并且可以进行简化,这个时候需要将其标记为传送冻结的结点,重新开始简化阶段。
溢出(spill) 简化和合并完成之后,冲突图中只剩下高度数(度数>=K)的节点,这个时候我们需要在图中选择一个高度数的结点,将它存入内存当中,然后将它压入栈中。这个时候其他结点的度数降低,可以继续进行简化。
选择(select) 对虚拟寄存器指派颜色,即分配真实的寄存器。具体做法是以一个空图开始,从栈中弹出一个节点,加入到冲突图中,并且为他指派一种颜色,该节点必须是可着色的,可着色的条件是其邻接结点使用的颜色小于真实的寄存器数K,对于简化阶段入栈的变量显然一定能够着色,对于溢出阶段入栈的变量,通过合并之后,邻接点中有一些变量的颜色相同,最后邻接点的颜色小于K种,能够进行着色,可以将其加入冲突图中,否则将其加入无法进行着色的集合中。
重新开始(restart) 如果无法进行着色的集合不为空,那么则需要改写程序,为这些变量在内存当中分配空间,并且在每次使用需要将其从内存当中取出,每次修改需要存进内存当中,这种情况下,溢出的临时变量会转变为几个活跃范围很小的新的临时变量,这个时候需要重新进行活跃分析、寄存器分配,直到没有溢出和简化为止(通常只需要迭代一两次)。
窥孔优化 对于相邻的部分少量指令进行优化。
处理无意义的加减法
旧指令
新指令
add/sub r0, r0, 0删除
add/sub r0, r1, 0move r0, r1
处理无意义的mov
处理对同一个dst的连续mov
旧指令
新指令
move r0, r1 move r0, r2 … move r0, rkmove r0, rk
处理向相邻块或者无意义块的跳转
旧指令
新指令
j next_blockMove r0, rk
处理向同一个地址的存储+加载的store+load对
旧指令
新指令
store a, memory load b, sameMemorymove b, a